
Hash Join
해시 테이블을 사용해서 매칭되는 행을 찾는 조인 방식
- Hash Join은 크게
build phase와probe phase두 단계로 구성된다.
1. Build Phase
1
2
3
SELECT given_name, country_name
FROM persons
JOIN countries ON persons.country_id = countries.country_id;
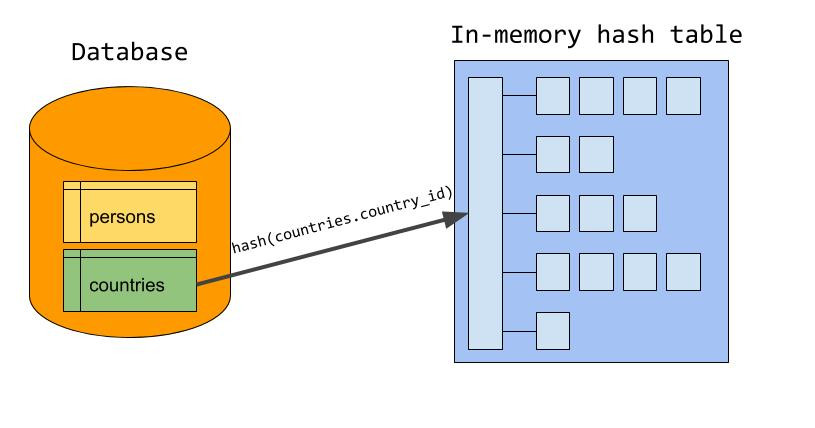
- 한쪽 입력을 기반으로 in-memory 해시 테이블을 만든다.
- 이때 해시 테이블의 key는 조인 조건(여기서는
country_id)이다. - 보통 더 작은 입력(바이트 크기 기준)을 해시 테이블로 만든다.
- 메모리에 올려야 하기 때문에 작은 쪽이 유리함.
- 예시에서 countries 테이블을 build input으로 선택했다고 가정하면:
- countries의 모든 country_id를 키로 해서 해시 테이블에 저장
- 이 과정을 마치면 build phase 종료
 (출처 : https://dev.mysql.com/blog-archive/hash-join-in-mysql-8/)
(출처 : https://dev.mysql.com/blog-archive/hash-join-in-mysql-8/)
2. Probe Phase
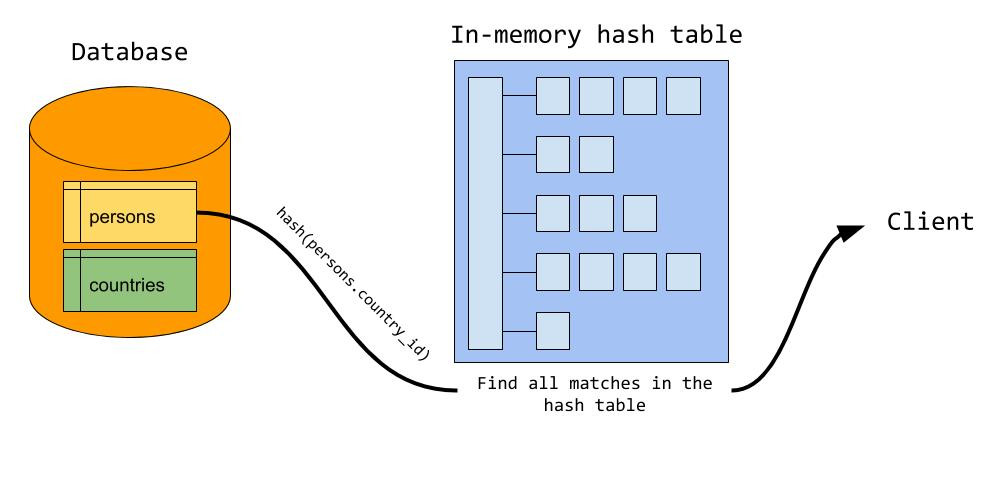
- 이제 서버는 probe input(예제에서는 persons)을 읽기 시작한다.
- 각 row에 대해:
persons.country_id값을 키로 해서, 해시 테이블에서 매칭되는 row를 찾는다.- 매칭되는 row가 있으면, 그 두 row를 합쳐서(joined row) 클라이언트로 보낸다.
즉, persons의 모든 row를 한 번씩만 읽고, 해시 테이블에서 상수 시간(constant time)으로 매칭을 찾게 된다.
- 이 방식이 잘 동작하려면 build input 전체를 메모리에 담을 수 있어야 한다.
- MySQL에서는 사용 가능한 메모리 크기를
join_buffer_size시스템 변수가 제어한다.- 이 값은 실행 중(runtime)에도 조정할 수 있다.
 (출처 : https://dev.mysql.com/blog-archive/hash-join-in-mysql-8/)
(출처 : https://dev.mysql.com/blog-archive/hash-join-in-mysql-8/)
Spill to disk
build input을 메모리에 다 올릴 수 없는 경우, 여러 개의 파일로 나눠서 디스크에 저장
1. Probe Phase에서의 Spill 처리
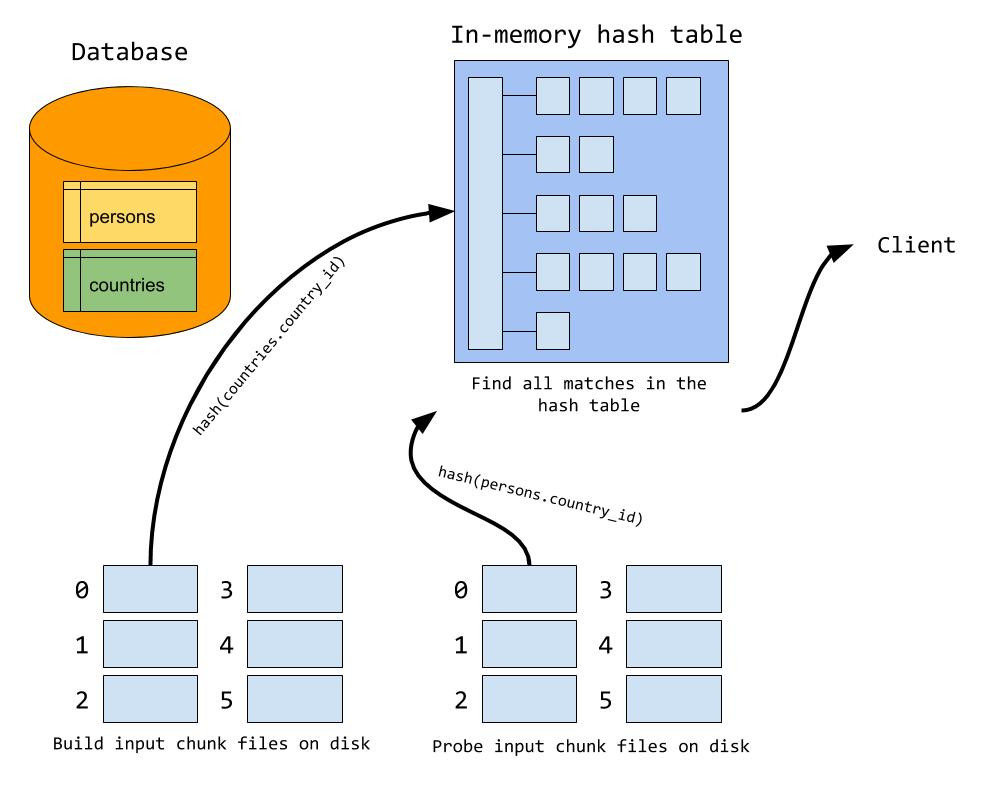
- MySQL은 build input을 여러 개의 chunk 파일로 나누어 저장:
- 예를 들어 build input이 1GB인데 메모리는 256MB라면
- 대략 4개의 chunk 파일로 나눠서 디스크에 쓰는 식
- 단, MySQL은 내부적으로 chunk 파일 최대 128개까지만 만들 수 있음
- 어떤 row가 어떤 chunk 파일로 들어갈지는 조인 키(예: country_id)에 대해 해시 값을 계산해서 정한다.
- 즉, 같은 키 값을 가진 row들은 항상 같은 chunk 파일에 들어가게된다.
- 이때 사용하는 해시 함수는, 나중에 메모리 안에서 사용하는 해시 함수와는 다르다.
2. Probe Phase에서의 Spill 처리
- build input 해시 테이블에 일치하는 row가 있는지 찾아야하는데, build input의 일부가 디스크에 있기 때문에 probe input의 row도 디스크에 있는 chunk와 짝을 맞춰야 한다.
- 따라서, probe input도 build input을 chunk file에 분배할때 사용한 동일한 해시 함수로 계산해서 chunk 파일을 만든다.
- 이렇게 하면 조인 키가 같은 row들은 반드시 같은 chunk 쌍(= build chunk + probe chunk)에 들어가게 된다.
3. Chunk File 처리
- 모든 chunk 파일 쌍을 처리:
- 첫 번째 build chunk를 읽어서 메모리에 해시 테이블로 만든다.
- 그에 대응하는 probe chunk를 읽어서 해시 테이블과 매칭시킨다.
- 끝나면 두 번째 chunk 쌍으로 넘어간다.
- 이런 식으로 모든 chunk 파일 쌍을 순차적으로 처리한다.
- build chunk를 읽어서 메모리에 해시 테이블로 만들때의 해시 함수는 input을 chunk file로 분배할 때의 해시 함수와는 다르다.
- 같은 해시 함수를 쓰면, chunk 파일에 있는 row들이 전부 같은 해시 값에 몰려서, 해시 테이블이 한쪽으로 쏠리는 문제(hash collision)가 생긴다.
 (출처 : https://dev.mysql.com/blog-archive/hash-join-in-mysql-8/)
(출처 : https://dev.mysql.com/blog-archive/hash-join-in-mysql-8/)
Chunk File 삭제는 ?
조인 결과가 클라이언트에게 전달된 뒤 바로 삭제
- 모든 chunk 파일 쌍이 조인을 마치면 다음을 수행:
HashJoinIterator::EndOfIteration()호출- 내부에서
cleanup로직 실행
- MySQL이
tmpdir에 만든 모든 chunk 파일을 닫고 삭제:- 파일 핸들을 닫은 다음, OS 레벨에서
unlink()호출을 수행 - 해시 테이블 메모리도
join_buffer_allocator가 release
- 파일 핸들을 닫은 다음, OS 레벨에서
사용 조건
| 유형 | 설명 | 사용 가능한 조인 조건 |
|---|---|---|
| (1) Hash Equi Join | build 테이블의 조인 키를 해시 테이블로 만들고, probe 테이블에서 같은 키 탐색 | 등가 조인 (=) 및 해당 조인 조건에 사용 가능한 인덱스가 없는 경우(물리적으로 인덱스가 있어도, 활용할 수 없는 경우도 포함) |
| (2) Hash Join (no condition) | 해시 테이블로 임시 저장 후, probe 단계에서 필터 조건( >, <, 등)으로 비교 | 비등가 조인, 조인 조건 없는 경우 |
- 예시
1
2
-- 기본 Hash Join (equi-join), c1에 인덱스 없음
SELECT * FROM t1 JOIN t2 ON t1.c1 = t2.c1;
1
2
3
-- 필터 조건만 있는 Hash Join (조인 조건 없음)
SELECT * FROM t1 JOIN t2
WHERE t1.c2 > 50;
1
2
-- Inner Non-Equi Join (비등가 조인)
SELECT * FROM t1 JOIN t2 ON t1.c1 < t2.c1;
1
2
3
-- Semijoin (IN 서브쿼리)
SELECT * FROM t1
WHERE t1.c1 IN ( SELECT t2.c2 FROM t2 );
1
2
3
-- Antijoin (NOT EXISTS)
SELECT * FROM t2
WHERE NOT EXISTS (SELECT * FROM t1 WHERE t1.c1 = t2.c1);
1
2
3
-- Left Outer Join
SELECT * FROM t1
LEFT JOIN t2 ON t1.c1 = t2.c1;
- 실행계획 결과
| 상황 | Extra 출력 | 의미 |
|---|---|---|
| 등가조인 | Using join buffer (hash join) | 일반 hash join (키 기반) |
비등가조인 (<, >, !=) | Using where; Using join buffer (hash join) | hash join (no condition) — 키 매칭 없음, 필터 조건으로 비교 |
| 조인 조건 없음 (카티션 곱) | Using join buffer (hash join) 또는 Using where 없이 | hash join (no condition) — 전 행 조합 |
메모리 관련
- Hash Join에서 사용하는 메모리는
join_buffer_size변수로 제어된다.- Hash Join은 필요할 때마다(join 진행 중) 메모리를 점진적으로 할당한다.
- 따라서,
join_buffer_size를 크게 설정해도 작은 쿼리가 불필요하게 큰 버퍼를 점유하지 않는다. - 단, Outer Join의 경우 전체 버퍼를 한 번에 할당한다.
- Hash Join이 필요로 하는 메모리가 이 크기를 초과하면, MySQL은 디스크 임시 파일을 사용(spill)한다.
- 이때 디스크 파일 수가
open_files_limit을 넘으면 조인이 실패할 수도 있다.