
※ 해당 내용은 ‘실전 아파치 카프카(한빛미디어)’ 1장을 읽고 필요한 부분을 정리한 내용입니다.
Apache Kafka란?
카프카는 분산 메세징 시스템이다
- 분산
- 분산 시스템(distributed system, 또는 분산 컴퓨팅)
- 서로 다른 시스템에 위치한 구성 요소들간에 통신하고 협력하여 구성되는 시스템
- 구성 요소는 컴퓨터, 물리적 서버, 가상 시스템, 컨테이너 등이 될 수 있다.
- 사용자에게는 하나의 시스템처럼 보인다.
- 일반적으로 분산 시스템은 확장성, 안정성, 성능 면에서 이점을 지닐 수 있다.
- 메세징 시스템
- 메세지를 받고 받은 메세지를 다른 시스템이나 장치에 보낸다
분산 이벤트 스트리밍 플랫폼이라고도 불린다- 이벤트 스트리밍이란 ?
- 데이터베이스, 센서, 모바일 장치, 클라우드 서비스 및 소프트웨어 애플리케이션과 같은 이벤트 소스로부터 스트림의 형태로 이벤트(데이터)를 실시간으로 캡처하는 작업이다.
- 이벤트 스트리밍 플랫폼은 이러한 이벤트 스트림을 나중에 검색할 수 있도록 영구적으로 저장하고, 이벤트 스트림을 실시간으로 조작, 처리 및 대응한다.
- 이벤트 스트리밍이란 ?
탄생 배경
- 링크드인(LinkedIn)에서 생성되는 로그를 처리하여, 사용자들의 웹사이트 활동을 추적하는 것을 목적으로 개발되었다.
(더 자세한 내용은 링크드인 블로그 참조) - 당시, 많은 기업들에서는 빅데이터를 어떻게 활용할 것인지가 화두였고 이를 위해 로그를 활용하기 시작했다.
- 링크드인이 실현하려고 했던 목표는 다음과 같다.
- 데이터를 높은 처리량으로 실시간 처리
- 수백 밀리초 ~ 수 초 내에 데이터 수집에서 처리까지 완료한다.
- 임의의 타이밍에 데이터를 읽는다
- 데이터를 사용하는 목적에 따라 꼭 실시간이 아니라 배치 처리도 가능하도록 한다.
- 다양한 제품과 시스템에 쉽게 연동한다
- 링크드인에서 데이터의 발생원이 되는 시스템이 다양했기 때문에, 여러 시스템을 통해 데이터를 받아들여야 했다.
- 메세지를 잃지 않는다
- 사용자 활동을 추적하는 것이 목표였기 때문에 약간의 중복이 있더라도 메세지를 잃지 않는 것이 중요했다.
- 메세지 중복을 허용하지 않도록 건마다 관리하면, 처리 오버헤드가 커지기 때문에 ‘높은 처리량으로 실시간 처리’라는 목적을 달성하기가 어렵다.
- 데이터를 높은 처리량으로 실시간 처리
목표 실현하기
링크드인은 위에서 언급한 목표를 실현하기 위해 크게 4가지 방법을 사용했다.
1. 메세징 모델과 스케일 아웃형 아키텍처
- 목표
- 높은 처리량으로 실시간 처리
- 임의의 타이밍에 데이터 읽기
- 다양한 제품과 시스템에 쉽게 연동
- 이러한 목표 달성을 위해 카프카는
메세징 모델을 채택했다.
일반적인 메세징 모델
- 메세징 모델은 일반적으로
Producer,Broker,Consumer로 구성된다. - 대표적인 메세징 모델로는
Queuing모델과Publish/Subscribe(Pub/Sub)모델이 있다. - Queuing 모델
- 브로커 안에 있는 큐에 프로듀서의 메세지가 담기고, 컨슈머가 큐에서 메세지를 추출한다.
- 여러 개의 컨슈머로 확장하여 메세지를 추출할 수 있어 병럴 처리가 가능하다.
- 하나의 컨슈머가 메세지를 받으면 다른 컨슈머는 해당 메세지를 받을 수 없다. 즉, 하나의 메세지는 여러 컨슈머 중 어느 하나에서 처리된다.
- 큐에서 추출되어 컨슈머에 도달한 메세지는 사라진다.

- Pub/Sub 모델
- Publisher = Producer
- Subscriber = Consumer
- Publisher는 브로커 내의
Topic이라고 불리는 스토리지에 메세지를 발행한다. - Subscriber는 여러 개의 토픽 중 원하는 것만 구독하여 메세지를 수신한다.
- 여러 Subscriber가 동일한 토픽을 구독하면, 큐잉 모델과는 달리 하나의 메세지가 여러 Subscriber(컨슈머)에게 도달할 수 있다.

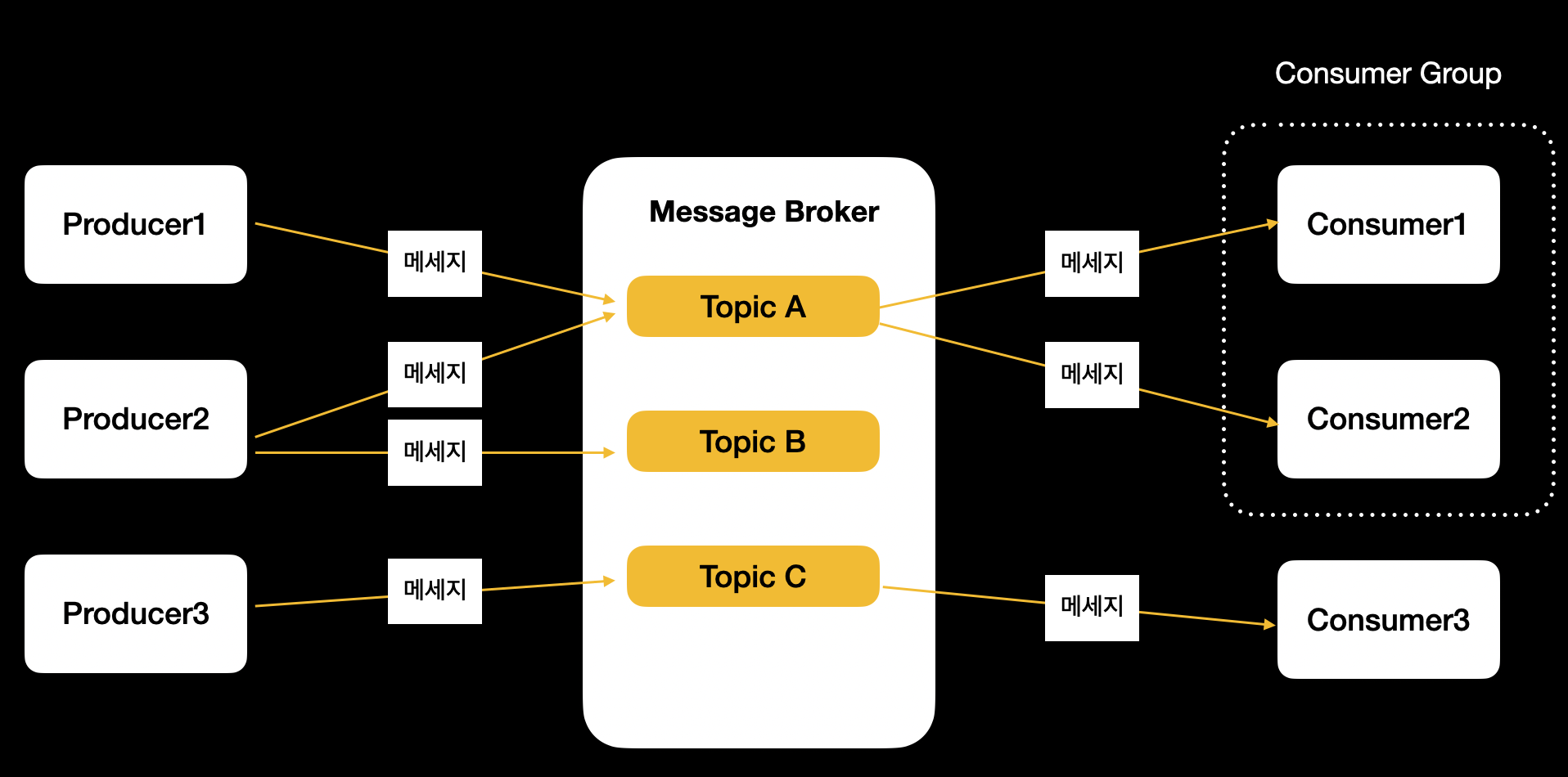
카프카의 메세징 모델과 스케일 아웃형 아키텍처
높은 처리량을 실현하기 위해서는 어떻게 확장성 있는 구성을 할 수 있을지가 관건이다
- 카프카는
컨슈머 그룹이라는 개념을 도입해서 두 가지 메세징 모델의 특징을 살린 모델을 구현한다.- Queuing 모델의 특징 : 병렬 처리(여러 컨슈머가 분산 처리로 메세지 소비)
- Pub/Sub 모델의 특징 : 동일한 메세지를 여러 구독자에게 전달하고, 토픽을 기반으로 메세지 분류
- 결과적으로, 카프카의 메세징 모델은 Pub/Sub 모델을 기반으로 컨슈머 그룹 내에서 분산 처리를 할 수는 구조이다.
- 카프카는 고가용성과 확장성을 위해 브로커를 복수로 구성하여 스케일 아웃형 아키텍처를 구성한다.
2. 디스크로의 데이터 영속화
- 목표
- 임의의 타이밍에 데이터를 읽는다.
- 메세지를 잃지 않는다.
- 배치 처리를 위해 데이터를 일정 기간마다 메모리에서만 유지하는 것은 용량 면에서 불가능하다.
- 따라서, 카프카의 메세지 영속화는 디스크에서 이루어진다.
- 디스크에 영속화하지만 높은 처리량을 제공한다.
- 장기 보존을 목적으로 영속화가 가능하기 때문에 카프카를 ‘스토리지 시스템’으로도 간주할 수 있다.
- 커밋 로그를 축적하기 위한 스토리지 시스템을 예로 들 수 있다.
카프카의 영속화
- 카프카는 브로커의 메모리에 실리면 송신 완료(메모리에서 디스크로의 flush는 OS에게 맡김)라는 사상을 갖고 있다.
- flush 간격을 OS에 전적으로 맡기지 않고 카프카 파라미터로 지정할 수도 있다.
- 따라서, 카프카에서의 데이터 영속화는 반드시 데이터 자체에 대한 내결함성(fault-tolerance)을 향상시키기 위한 것은 아니라고 이해할 수 있다.
- 오히려 메세지 복제 구조를 통해, 단일 브로커의 고장이 발생하더라도 데이터 손실로 이어지지 않는다고 이해하는 것이 자연스럽다.
3. 이해하기 쉬운 API 제공
- 목표
- 다양한 제품과 시스템에 쉽게 연동
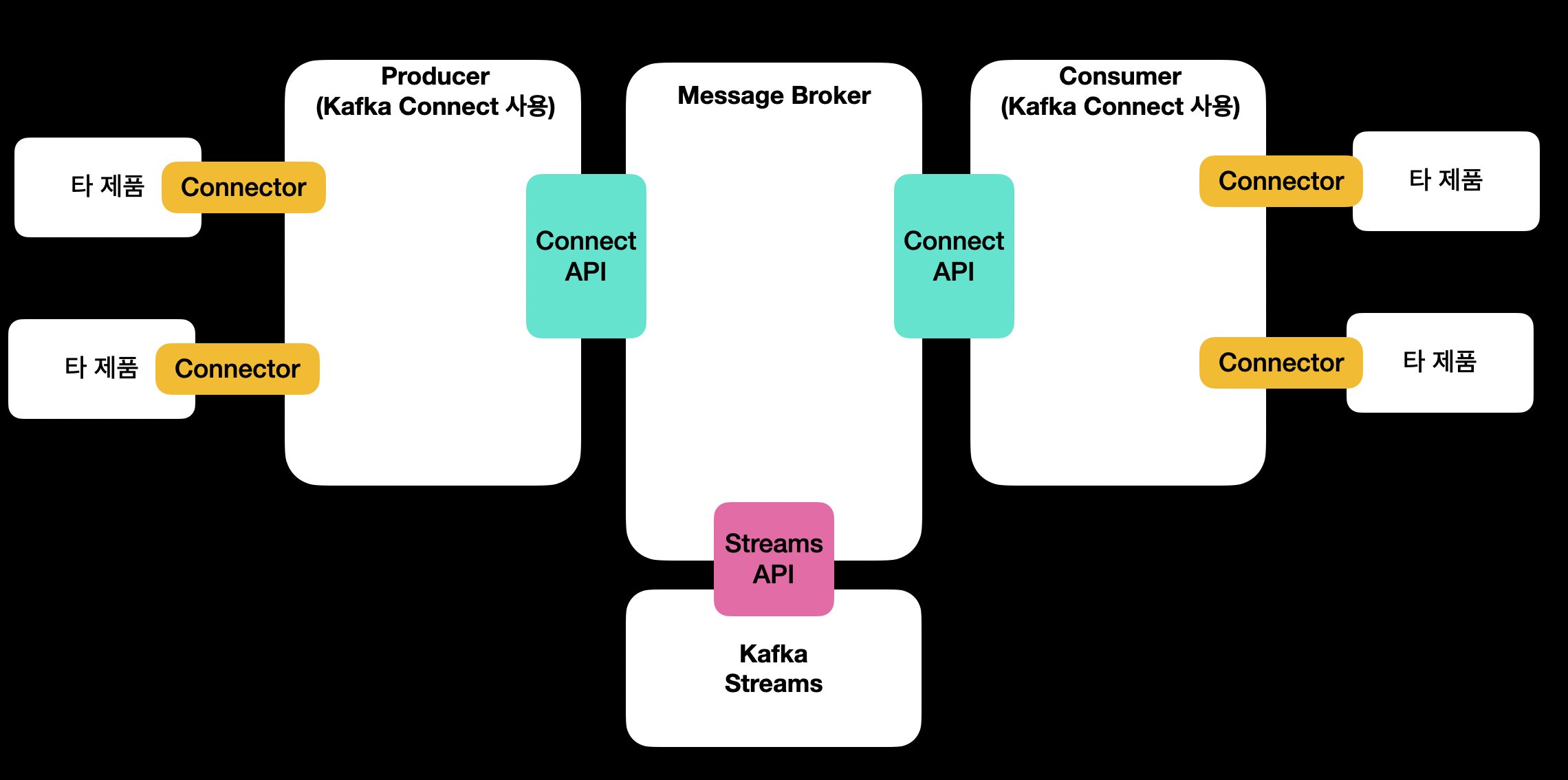
- 카프카는 프로듀서와 컨슈머가 쉽게 접속할 수 있도록
Connect API를 제공한다.- 프로듀서와 컨슈머는 이를 이용하여 브로커와의 상호 교환이 가능하다.
- API를 기반으로 타 제품과의 접속에 관한 공통 부분을 프레임워크화한
Kafka Connect와 제품별 커넥터도 있다. - 카프카의 스트림 데이터 처리를 위한
Streams API와 이를 이용한Kafka Streams도 제공된다.
4. 전달 보증
- 목표
- 메세지를 잃지 않는다.
- 프로듀서 입장에서는 당연히 중간에 메세지가 유실되지 않고 컨슈머까지 전달되어야 한다.
- 이를 위해 카프카는 ‘전달 보증(delivery guarantees)’ 기능을 제공한다.
| 종류 | 브로커에서 메시지 처리 | 재전송 유무 | 중복 삭제 유무 | 메시지 유실 여부 |
|---|---|---|---|---|
| At Most Once | 0 또는 1회 | X | X | 유실될 수 있다. |
| At Least Once | 1회 또는 그 이상 | O | X | 유실 가능성이 낮다. |
| Exactly Once | 1회 | O | O | 유실 가능성이 매우 낮다. |
- 카프카 개발 초기에는 높은 처리량을 구현해야 했기 때문에 Exactly Once 수준의 보증은 미루고 최소한 메세지 유실을 방지하고자 At Least Once 수준으로 전달을 보증했다.
Ack와 Offset Commit
- Ack
- 브로커가 메세지를 수신했을 때 프로듀서에게 수신 완료했다는 응답
- 이것을 이용해 프로듀서는 재전송 여부를 판단할 수 있다.
acks = 0이면 at most once 수준의 전달 보증acks = 1이면 at least once 수준의 전달 보증 (default)acks = all이면 exactly once 수준의 전달 보증 (acks 이외에 enable.idempotence 등의 설정도 필요하다.)
- Offset Commit
- Offset : 컨슈머가 어디까지 메세지를 받았는지를 관리하기 위한 지표
- Offset Commit : 오프셋을 이용해 전달 보증을 실현하는 구조
- 브로커는 오프셋 커밋을 통해 오프셋을 업데이트한다. 즉, 컨슈머가 메세지를 처리(수신)한 기록을 남기는 것이다.
- 이를 통해 메세지를 재전송할 때도 어디서부터 재전송하면 되는지 판단할 수 있다.

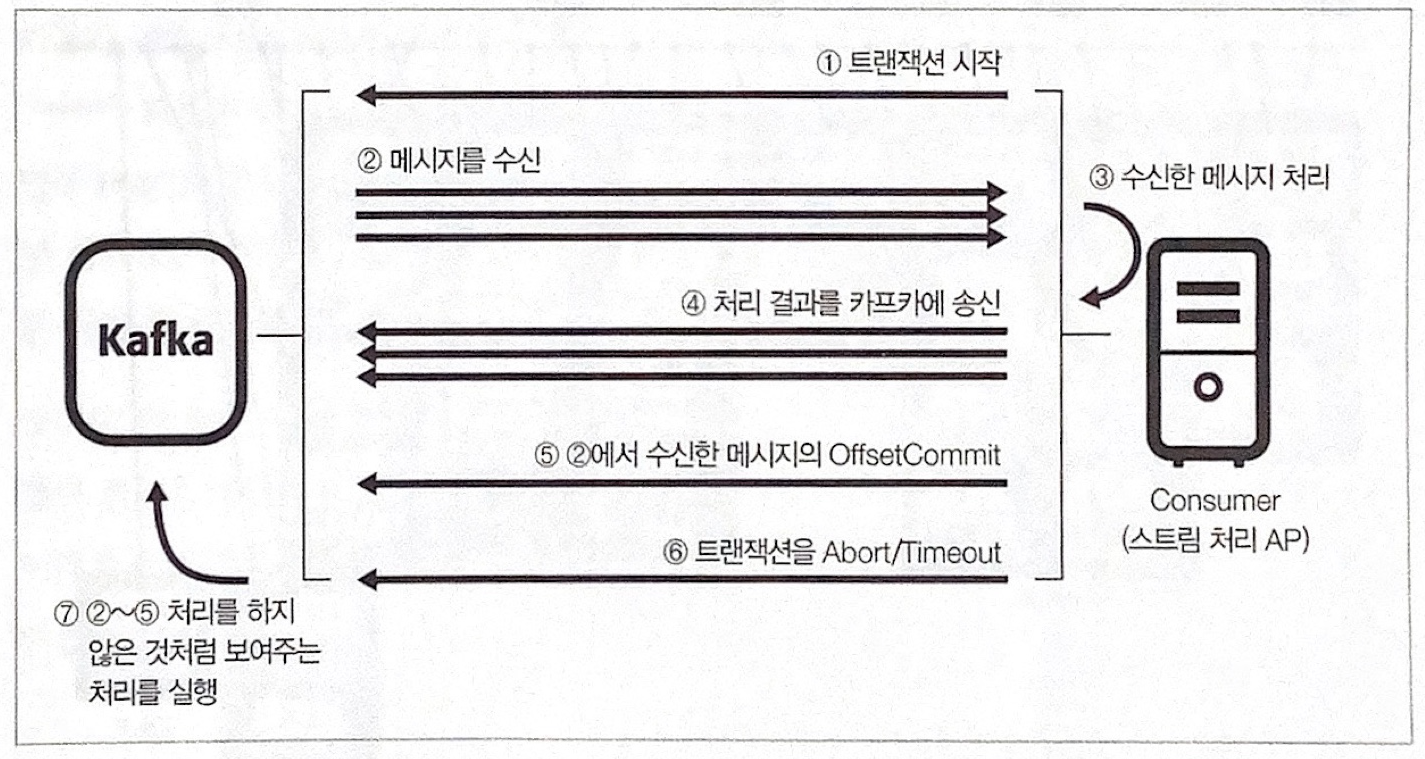
Exactly Once 구현
- 카프카의 유용성이 높아지면서 Exactly Once 수준의 전달을 보증하고자 하는 요구가 높아졌다.
- 이를 위해 카프카에 트랜잭션 개념을 도입하게 되었다.
- Exactly Once를 보증하기 위해서는 프로듀서, 컨슈머 측에서의 구현 도 필요하다.

요약
카프카의 특징
- 확장성 : 여러 서버로 scale out할 수 있기 때문에 데이터 양에 따라 시스템 확장이 가능하다.
- 영속성 : 수신한 데이터를 디스크에 유지할 수 있기 때문에 언제라도 데이터를 읽을 수 있다
- 유연성 : 연계할 수 있는 제품이 많기 때문에 허브 역할을 한다.
- 신뢰성 : 메세지 전달 보증을 하므로 데이터 분실을 걱정하지 않아도 된다.
카프카의 목표와 실현 방법

참고자료
- 사사키 도루 외 4인, 『실전 아파치 카프카』, 한빛미디어(2020), 1장
- https://kafka.apache.org/documentation/#
- https://blog.stackpath.com/distributed-system/