
Kafka Connect
Apache Kafka와 다른 데이터 시스템 간에, 데이터를 확장 가능하고 안정적으로 스트리밍하기 위한 도구
- 대규모 데이터를 Kafka로 가져오거나 Kafka에서 내보내는 커넥터를 빠르고 간단하게 정의할 수 있게 해준다.
- 전체 데이터베이스를 가져오거나, 애플리케이션 서버 전반에서 수집한 메트릭(metrics)을 Kafka 토픽으로 전송하여 낮은 지연(latency)으로 스트림 처리에 활용할 수 있다.
- 내보내기 작업(export job)을 통해 Kafka 토픽의 데이터를 보조 스토리지나 조회 시스템, 또는 배치(batch) 시스템으로 전달하여 오프라인 분석에 사용할 수도 있다.
주요 특징
1. Kafka 커넥터를 위한 공통 프레임워크
- Kafka Connect는 외부 데이터 시스템과 Kafka 간의 통합을 표준화하여, 커넥터의 개발·배포·관리를 단순화한다.
2. 분산(distributed) 모드와 단일(standalone) 모드 지원
- 대규모 중앙 관리형 서비스로 확장하거나, 개발·테스트·소규모 운영 환경에 맞게 축소하여 사용할 수 있다.
3. REST 인터페이스 제공
- 간단한 REST API를 통해 Kafka Connect 클러스터에 커넥터를 등록하고 관리할 수 있다.
4. 자동 오프셋(offset) 관리
- 커넥터가 최소한의 정보만 제공해도 Kafka Connect가 오프셋 커밋 과정을 자동으로 관리한다.
5. 분산 및 확장 가능 구조
- Kafka Connect는 Kafka의 그룹 관리 프로토콜(group management protocol)을 기반으로, 워커를 추가하기만 해도 클러스터 규모를 손쉽게 확장할 수 있다.
핵심 개념
1. Connectors
Kafka Connect의 커넥터(connector)는 데이터가 어디에서 어디로 복사되어야 하는지를 정의
Source Connector
- 외부 데이터 소스에서 전체 데이터베이스를 가져오고, 테이블의 변경 사항을 실시간으로 Kafka 토픽으로 스트리밍
※ “전체 데이터베이스를 가져온다 (ingest entire database)” ?
단순히 DB 전체를 한 번에 복사한다는 뜻이 아니라, 초기 데이터 적재 단계에서의 동작을 의미
- 초기 적재 (Initial Snapshot / Full Load)
- CDC 파이프라인을 처음 시작할 때, 현재 데이터베이스에 들어있는 모든 테이블의 전체 데이터를 한 번 읽어서 Kafka로 보내는 단계
- CDC는 원래 “변경 사항만 감지”하지만, 시스템이 처음 시작할 때는 “기존 데이터”가 Kafka에 없기 때문에 초기 스냅샷이 필요
- 예시: MySQL의 경우, Debezium이 처음 시작할 때 각 테이블을
SELECT * FROM table식으로 읽음. - 그 데이터를 Kafka 토픽에 넣어 “현재 상태”를 맞춘 뒤, 이후부터는 binlog 기반의 변경 이벤트만 처리.
따라서, 테이블 크기가 크면,
전체 스캔(Full Table Scan),네트워크 전송 (DB → Kafka Connect),JSON 직렬화 → Kafka 발행까지 다 포함되어, DB I/O, 네트워크, Kafka 전송 지연이 한꺼번에 누적된다.- Debezium 설정
snapshot.mode로 스냅샷 방식을 제어할 수 있다.
| 모드 | 설명 |
|---|---|
initial | (기본값) 전체 데이터를 한 번 읽은 뒤 binlog로 전환 |
schema_only | 스키마만 가져오고 실제 데이터는 binlog로만 반영 |
never | 스냅샷 생략, 이미 target이 동기화되어 있는 경우 사용 |
initial_only | binlog로 넘어가지 않고 스냅샷까지만 수행 |
Sink Connector
Kafka 토픽에 저장된 데이터를 외부 시스템으로 내보내는 역할
- 커넥터가 구현하거나 사용하는 모든 클래스는 커넥터 플러그인(connector plugin) 안에 정의되어 있습니다.
즉, “커넥터 플러그인(plugin)”은 코드(클래스, 설정 등)가 들어 있는 구현 단위, “커넥터 인스턴스(instance)”는 그 플러그인을 실제로 실행 중인 작업 단위라고 할 수 있습니다.
- 둘 다 “커넥터(connector)”라고 부르기도 하지만, 맥락에 따라 의미가 구분됩니다.
예를 들어, “install a connector(커넥터를 설치한다)” → 플러그인(plugin)을 의미 “check the status of a connector(커넥터 상태를 확인한다)” → 인스턴스(instance)를 의미
- Confluent는 사용자가 가능한 한 기존 커넥터를 활용할 것을 권장
※ Confluent ?
- Apache Kafka의 상용 배포판을 만든 회사이자, Kafka의 창시자인 Jay Kreps가 공동 창립한 회사
| 항목 | 설명 |
|---|---|
| Kafka Connect | Apache Kafka의 공식 컴포넌트 (데이터 통합 프레임워크) |
| Confluent | Kafka 및 Connect를 포함한 상용 배포/운영 플랫폼 |
| Confluent Platform | Kafka Connect + Schema Registry + ksqlDB + 관리도구 등 포함 |
| Confluent Cloud | 완전관리형 Kafka 서비스 (Kafka Connect 포함) |
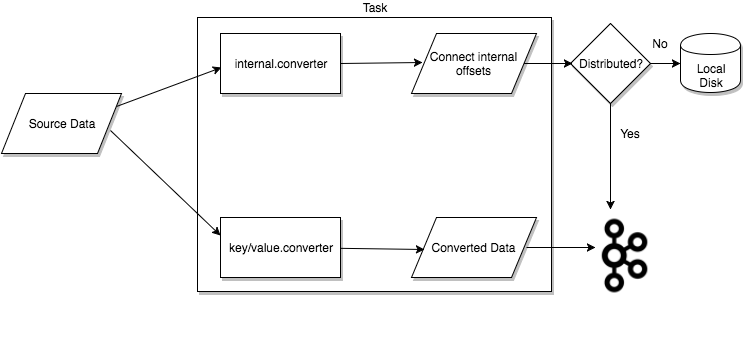
2. Tasks
Task가 실제로 데이터를 복사하는 작업을 수행
- 각 커넥터 인스턴스(connector instance)는 여러 개의 태스크(task)를 조정
커넥터가 하나의 작업(job)을 여러 태스크로 나누어 병렬로 실행할 수 있게 함으로써, Kafka Connect는 병렬 처리(parallelism) 와 확장 가능한 데이터 복제(scalable data copying) 를 복잡한 설정 없이도 기본적으로 지원
- 각 태스크 자체는 내부적으로 상태(state)를 저장하지 않습니다.
- 대신 태스크의 상태 정보는 Kafka의 특별한 토픽에 저장됩니다:
config.storage.topicstatus.storage.topic
- 이 상태들은 해당 커넥터 인스턴스가 관리합니다. 즉, 태스크는 무상태(stateless) 로 설계되어 있고, 필요할 때마다 Kafka 내부 토픽을 통해 상태를 복구하거나 관리할 수 있다.
- 태스크는 언제든지 시작(start), 중지(stop), 재시작(restart) 할 수 있습니다. 이런 구조 덕분에 Kafka Connect는 장애 복구(resilience) 와 확장성(scalability) 을 동시에 갖춘 안정적인 데이터 파이프라인을 제공
 (출처 : https://docs.confluent.io/platform/current/connect/index.html)
(출처 : https://docs.confluent.io/platform/current/connect/index.html)
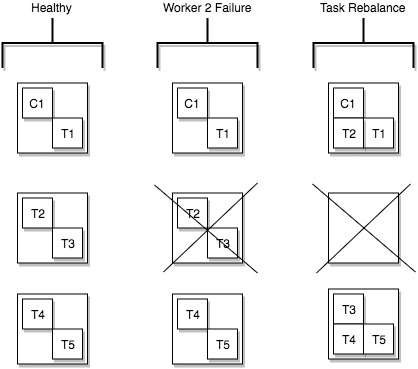
Task Rebalancing
- Kafka Connect에서 커넥터가 클러스터에 처음 등록되면, 클러스터 내의 모든 워커(worker)들이 협력하여 모든 커넥터와 태스크를 재분배(rebalance) 합니다.
이 과정을 통해 각 워커는 대략 동일한 양의 작업을 담당하게 됩니다.
- 리밸런싱 절차는 다음과 같은 상황에서도 수행됩니다:
- 커넥터가 필요한 태스크 개수를 늘리거나 줄일 때
- 커넥터의 설정이 변경될 때
- 워커가 장애로 인해 중단되었을 때, 남아 있는 활성 워커(active workers)들로 태스크가 재분배됨
즉, 클러스터는 항상 부하를 균등하게 분산시키는 방향으로 자동 조정된다.
- 태스크가 개별적으로 실패했을 때(task failure)는 리밸런싱이 자동으로 트리거되지 않는다.
- 태스크 실패는 일반적인 운영 시나리오가 아닌 예외적인 상황으로 간주되기 때문입니다.
- 따라서, 실패한 태스크는 Kafka Connect 프레임워크가 자동으로 재시작하지 않습니다.
- 대신 REST API 를 통해 수동으로 재시작해야 합니다.
 (출처 : https://docs.confluent.io/platform/current/connect/index.html)
(출처 : https://docs.confluent.io/platform/current/connect/index.html)
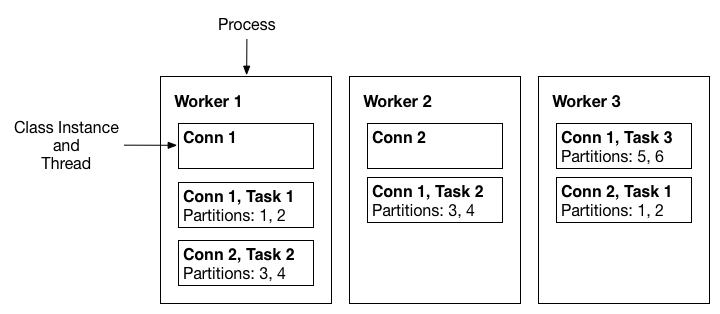
3. Workers
커넥터(Connector) 와 태스크(Task) 는 논리적인 작업 단위이므로, 이들이 실제로 실행되기 위해서는 어떤 프로세스(process) 위에 스케줄링되어야 합니다.
Kafka Connect에서는 이러한 프로세스를 워커(Worker) 라고 부릅니다.
Standalone Workers (단일 모드 워커)
Standalone 모드는 가장 단순한 실행 모드입니다. 하나의 프로세스가 모든 커넥터와 태스크를 직접 실행합니다.
- 특징:
- 설정이 매우 간단 (단일 프로세스만 실행)
- 개발 초기 단계나 테스트, 또는 단일 호스트에서 로그를 수집하는 등의 간단한 상황에 적합
- 모든 실행이 하나의 프로세스에서 처리됨
- 제한점:
- 확장성(scalability) 이 제한됨 (프로세스 1개가 전부)
- 장애 복구(fault tolerance) 불가능 (프로세스가 죽으면 전체 중단)
- 외부 모니터링을 붙이지 않으면 자동 복구 기능 없음
Distributed Workers (분산 모드 워커)
Kafka Connect의 확장성(scalability)과 자동 장애 복구(fault tolerance)를 제공하는 운영 환경용 모드
- 특징:
- 여러 워커 프로세스를 동일한 group.id 로 실행하면, 이들이 하나의 Connect 클러스터를 형성함.
- 워커들이 서로 협력하여 커넥터와 태스크를 자동으로 분산 배치.
- 워커를 추가하거나 중단하거나 장애가 발생하면, 남은 워커들이 이를 감지하고 태스크를 자동 재분배(rebalance) 함.
- 이 과정은 Kafka Consumer Group 리밸런싱과 유사한 방식으로 동작함.
- 예시:
- Worker A:
group.id = connect-cluster-a - Worker B:
group.id = connect-cluster-a - 두 워커는 자동으로 하나의 클러스터 connect-cluster-a 를 형성함.
- Worker A:
 (출처 : https://docs.confluent.io/platform/current/connect/index.html)
(출처 : https://docs.confluent.io/platform/current/connect/index.html)
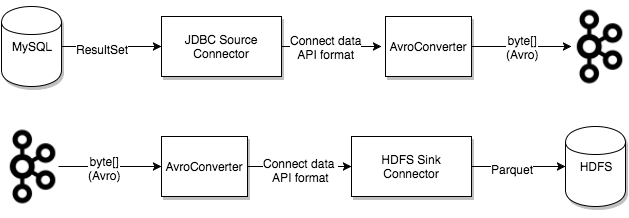
4. Converters
Kafka Connect가 외부 시스템과 데이터를 주고받을 때, 데이터를 Kafka 내부 형식(바이트 배열)과 Connect의 내부 데이터 구조 사이에서 변환해주는 역할
즉, Task가 데이터를 처리할 때, 컨버터를 사용하여 바이트 형태의 데이터를 Kafka Connect 내부 데이터 형식으로 변환하거나, 반대로 내부 형식을 바이트로 직렬화
예시:
| 컨버터 | 설명 |
|---|---|
| JsonConverter | 데이터를 JSON 형태로 변환 |
| StringConverter | 단순 문자열로 변환 |
| AvroConverter | Avro 스키마를 기반으로 변환 (주로 Schema Registry와 함께 사용) |
| ProtobufConverter | Protobuf 포맷으로 직렬화/역직렬화 |
| ByteArrayConverter | 원시 바이트 그대로 처리 (가공 없이 전송할 때) |
- 컨버터는 커넥터로부터 독립적으로 분리되어 설계되어 있다.
- 따라서, 커넥터는 자신이 다루는 데이터 소스나 타깃(DB, 파일 등)에 집중할 수 있고
- 데이터의 표현 방식(Avro, JSON, String 등)은 컨버터가 전담
 (출처 : https://docs.confluent.io/platform/current/connect/index.html)
(출처 : https://docs.confluent.io/platform/current/connect/index.html)
5. Transforms
하나의 레코드를 입력받아 수정된 레코드를 출력하는 간단한 함수
- 레코드 ?
- 커넥터가 주고받는 한 건의 데이터 이벤트를 의미
- Source Connector → Kafka 로 데이터를 보낼 때:
SourceRecord - Kafka → Sink Connector 로 데이터를 보낼 때:
SinkRecord
orders테이블에서 한 행이 변경됐을때, Debezium 같은 Source Connector가 다음과 같은SourceRecord를 생성
1
2
3
4
5
6
7
8
9
10
11
{
"topic": "dbserver1.inventory.orders",
"key": { "order_id": 101 },
"value": {
"order_id": 101,
"status": "SHIPPED",
"amount": 30000
},
"timestamp": 1735200000000,
"schema": { ... }
}
Source Connector에서의 Transform 동작
Source Connector → Transform 1 → Transform 2 → … → Kafka
- Source Connector 가 새로운 소스 레코드를 생성하면, Kafka Connect는 그 레코드를 첫 번째 변환(Transform)으로 전달한다.
- 변환이 수행되어 수정된 새로운 레코드가 생성된다.
- 이 결과 레코드는 다음 변환으로 전달되고, 같은 방식으로 반복된다.
- 마지막 변환을 거친 최종 레코드는 바이너리 형태로 직렬화되어 Kafka에 저장된다.
Sink Connector에서의 Transform 동작
Kafka → Transform 1 → Transform 2 → … → Sink Connector
- Kafka Connect는 Kafka 토픽으로부터 메시지를 읽어 바이너리 데이터를 Sink Record 로 변환한다.
- 변환이 설정되어 있으면, 그 레코드는 첫 번째 변환을 거친다.
- 수정된 레코드는 다음 변환으로 전달되어 또 한 번 갱신된다.
- 모든 변환을 거친 최종 Sink Record가 Sink Connector 로 전달되어 최종 처리된다.
예시1
토픽 이름 변경 (RegexRouter 사용)
1
2
3
4
"transforms": "routeByStatus",
"transforms.routeByStatus.type": "org.apache.kafka.connect.transforms.RegexRouter",
"transforms.routeByStatus.regex": "orders",
"transforms.routeByStatus.replacement": "orders.${order_status}"
RegexRouter변환은 메시지가 들어가는 토픽 이름을 동적으로 변경한다.${order_status}같은 필드를 사용해 메시지 값(value)에 따라 라우팅이 가능 (다만 기본 SMT는 값 참조를 직접 지원하지 않으므로, 커스텀 Transform으로 구현하기도 한다.)
- 결과적으로,
orders.NEW,orders.CANCELLED처럼 주문 상태에 따라 다른 토픽으로 전송됨
예시2
특정 필드 제거
1
2
3
"transforms": "removePII",
"transforms.removePII.type": "org.apache.kafka.connect.transforms.ReplaceField$Value",
"transforms.removePII.blacklist": "ssn,email"
ssn,email같은 개인정보 필드를 메시지에서 제거
6. Dead Letter Queue
Sink Connector에서 처리할 수 없는 잘못된 레코드를 별도 토픽으로 보내는 에러 처리 메커니즘
- Dead Letter Queue(DLQ)는 Sink Connector에서만 사용되는 기능
- 즉, Sink Connector에서 형식 불일치나 변환 오류 등으로 특정 레코드를 처리할 수 없을 때, 실패한 레코드를 특별한 Kafka 토픽(Dead Letter Queue Topic)으로 따로 보관한다.
- 예시 :
- Kafka 메시지는 JSON 형식인데, Sink Connector는 Avro 형식을 기대하고 있을 때
- 메시지에 필수 필드가 누락되었을 때
- 스키마 호환성 문제로 Sink 시스템에 쓸 수 없을 때
- 이런 경우, Kafka Connect는
errors.tolerance설정에 따라 대응한다.
| 설정값 | 의미 |
|---|---|
| none (기본값) | - 오류 발생 시 즉시 태스크 실패. 커넥터는 실패 상태(failed)가 되어 중단됨 - 운영자는 Worker 로그를 확인하고 원인을 수정한 뒤 커넥터를 재시작해야 함 |
| all | - 모든 오류나 잘못된 레코드를 무시하고 계속 처리. 다만 로그에는 기록되지 않음. - 따라서, 실패한 레코드 수를 확인하려면 내부 메트릭(metrics)이나 원본과 결과의 카운트를 비교해야 한다. |
errors.tolerance=all로 설정된 경우, 추가 설정을 통해 실패한 레코드를 DLQ 토픽으로 자동 전송할 수 있다.
1
2
errors.tolerance = all
errors.deadletterqueue.topic.name = <dead-letter-topic-name>
- 기본적으로 DLQ 토픽에는 레코드 데이터만 저장되며, “왜 실패했는지”에 대한 정보가 없다.
- 아래 옵션을 추가해서 에러 메타데이터를 함께 기록할 수 있다.
1
errors.deadletterqueue.context.headers.enable = true
- 이 설정을 켜면 DLQ에 전송되는 레코드의 헤더에 에러 원인 정보가 추가된다.
- 헤더 키들은
_connect.errors.로 시작하며,kafkacat같은 도구로 이 헤더를 읽어보면 실패 이유를 직접 확인할 수 있다. - 예:
1
2
_connect.errors.exception.class=org.apache.kafka.connect.errors.DataException
_connect.errors.exception.message=Invalid schema