
※ 해당 내용은 ‘실전 아파치 카프카(한빛미디어)’ 2장을 읽고 필요한 부분을 정리한 내용입니다.
분산 메세징 처리를 위한 시스템 구성

1. 파티션
- 브로커상의 데이터를 읽고 쓰는 것은 파티션이라는 단위로 분할되어 있다.
- 파티션 단위로 나누는 이유는 토픽에 대한 대량의 메세지 입출력을 지원하기 위함이다.
- 즉, 파티션은 브로커 클러스터 안에 분산 배치되어 메세지 수신/전달을 분산해서 수행함으로써 처리량을 높인다.
2. 컨슈머 그룹
- 단일 토픽이나 여러 파티션에서 메세지를 취득하기 위해 ‘컨슈머 그룹’이라는 개념이 존재한다.
- 카프카 클러스터 전체에서 글로벌 ID를 컨슈머 그룹 전체에서 공유한다.
- 여러 컨슈머는 자신이 소속한 컨슈머 그룹을 식별해, 읽어들일 파티션을 분류하고 재시도를 제어한다.
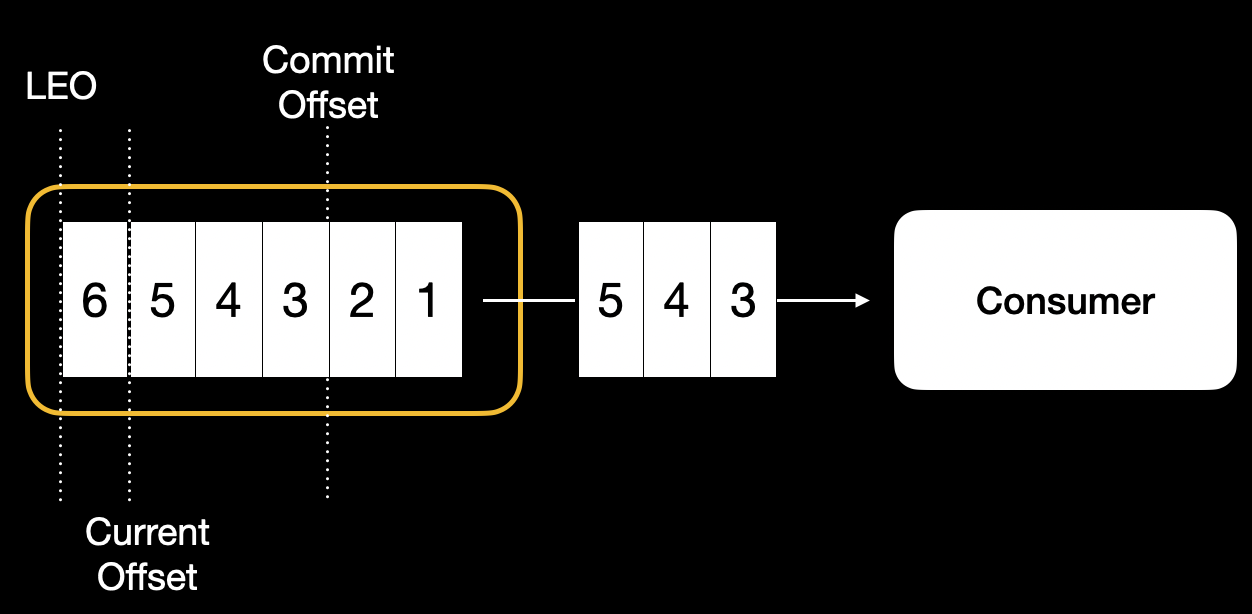
3. 오프셋
- 파티션 내에서 메세지의 위치(파티션에서 수신한 메세지에는 일련번호가 부여된다)를 나타내는 정보
- 오프셋을 활용해 컨슈머가 취득하는 메세지의 범위 및 재시도를 제어한다.
- 오프셋의 종류는 다음과 같다.
- Log-End-Offset(LEO) : 파티션 데이터의 끝을 나타낸다.
- 브로커에 의해 파티션에 관한 정보로 관리, 업데이트된다.
- Current Offset : 컨슈머가 어디까지 메세지를 읽었는지를 나타낸다.
- 컨슈머에서 데이터를 취득하면 업데이트된다.
- Commit Offset : 컨슈머가 어디까지 커밋했는지를 나타낸다.
- 컨슈머 그룹마다 보관, 관리, 업데이트된다.
- Log-End-Offset(LEO) : 파티션 데이터의 끝을 나타낸다.
4. 주키퍼
Apache Zookeeper는 분산 처리를 위한 관리 도구이다.(coordination service system)- 카프카의 분산 메세징 처리를 위한
메타 데이터(토픽, 파티션 등)를 관리한다. - 주키퍼 클러스터의 구조상 홀수로 구성하는 것이 일반적이다.
코디네이션 서비스의 필요성 (출처 : 조대협님 블로그)
- 분산 시스템을 설계 하다보면, 다음과 같은 문제에 부딪힌다.
- 분산된 시스템간의 정보 공유를 어떻게 할 것인지
- 클러스터에 있는 서버들의 상태 체크를 어떻게 할 것인지
- 분산된 서버들간에 동기화를 위한 락(lock) 처리를 어떻게 할 것인지
- 코디네이션 서비스는 분산 시스템 내에서 중요한 상태 정보나 설정 정보 등을 유지함으로써 위와 같은 문제를 해결해준다.
- 따라서, 코디네이션 서비스의 장애는 전체 시스템의 장애를 유발하기 때문에, 이중화 등을 통하여 고가용성을 제공해야 한다.
- ZooKeeper는 이러한 특성을 잘 제공하기 때문에 유명한 분산 솔루션에 많이 사용되고 있다.
- 코디네이션 서비스는 데이터 액세스가 빨라야 하며, 자체적으로 장애에 대한 대응성을 가져야 한다.
- Zookeeper는 자체적으로 클러스터링을 제공하여 장애에도 데이터 유실 없이 fail over/fail back이 가능하다.
메세지 송수신을 위한 시스템 구성
1. 메세지와 토픽
- 메세지
- 카프카에서 다루는 데이터의 최소 단위
- Key, Value를 갖는다.
- 토픽
- 메세지를 종류별로 관리하는 스토리지
- 브로커에 배치되어 관리된다.
2. 브로커
- 메세지를 수신/전달하는 역할을 담당한다.
- 하나의 서버(또는 인스턴스)당 하나의 데몬 프로세스로 동작한다.
- 여러 대의 클러스터로 구성할 수 있으며, 브로커를 추가함으로써 처리량 향상(스케일 아웃)이 가능하다.
※ 클러스터 : 여러 대의 컴퓨터들이 연결되어 하나의 시스템처럼 동작하는 컴퓨터들의 집합
브로커의 데이터 보관 기간
- 스토리지 용량 제한이 있기 때문에 기간을 무제한으로 둘 수는 없다.
- 일반적으로 데이터 삭제를 위해 다음 두 가지 정책으로 사용한다.
- 오래된 메세지 삭제
- 브로커 파라미터 :
cleanup.policy : delete - 지정한 시간보다 오래된 데이터가 삭제된다(default : 1주)
- 축적 데이터 크기가 지정한 데이터 크기보다 커진 경우(default : 크기 제한 없음)
- 브로커 파라미터 :
- 압축
- 브로커 파라미터 :
cleanup.policy : compact - 최신 Key의 데이터를 남겨두고 중복하는 Key의 오래된 메세지가 삭제된다.
- 동일한 Key에 대해서는 항상 최신의 Value만 얻을 수 있으면 되는 상황에서 사용한다.
- 브로커 파라미터 :
- 오래된 메세지 삭제
3. 프로듀서
프로듀서/컨슈머를 구현하는 기능은 브로커로 데이터를 보내고 브로커에서 데이터를 받기 위한 라이브러리로 제공된다.
프로듀서 API를 이용하여 브로커에 데이터를 송신하기 위해 구현된 애플리케이션이다.- 프로듀서 API를 내포한 도구, 미들웨어를 통해 이용하는 형태 등 다양하다.
프로듀서의 메세지 송신
- 파티션에 메세지를 송신할 때, 버퍼 기능처럼 프로듀서의 메모리를 이용하여 일정량 축적 후 송신(배치 처리)할 수 있다.
- 수 바이트 ~ 수십 바이트의 작은 메세지를 대량으로 브로커에 송신하는 상황을 가정해보자.
- 이런 경우 하나의 메세지당 1회씩 송신되면, 네트워크의 지연으로 인해 처리량에 영향을 줄 수 있다.
- 하지만, 처리의 지연시간은 증가되므로 처리량과 지연 시간의 트레이드 오프를 고려한 설계가 필요하다.
- 배치 처리시, 메세지를 송신하는 트리거는 다음과 같다.
- 지정된 크기에 도달한 경우 (설정값 :
batch.size) - 지정한 대기 시간에 도달한 경우 (설정값 :
linger.ms)
- 지정된 크기에 도달한 경우 (설정값 :
파티셔닝
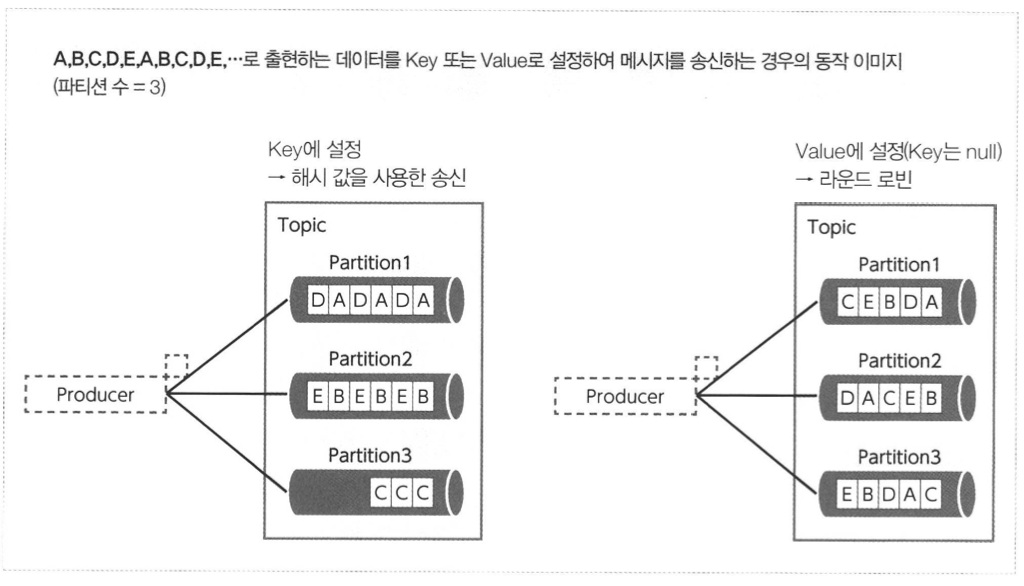
- 프로듀서에서 송신하는 메세지를 어떻게 파티션을 보낼지 결정하는 것
- 메세지 Key의 해시 값을 사용한 송신
- 메세지의 Key를 명시적으로 지정함으로써 Key에 따라 송신처 파티션을 결정한다.
- 파티션 클래스에는 partitionId라는 멤버 변수가 있어 ID에 의해 관리된다.
- 라운드 로빈에 의한 송신
- 라운드 로빈 방식 : 순서대로 할당
- 메세지 Key를 null로 지정한 경우, 여러 파티션으로의 메세지 송신을 라운드 로빈 방식으로 실행한다.
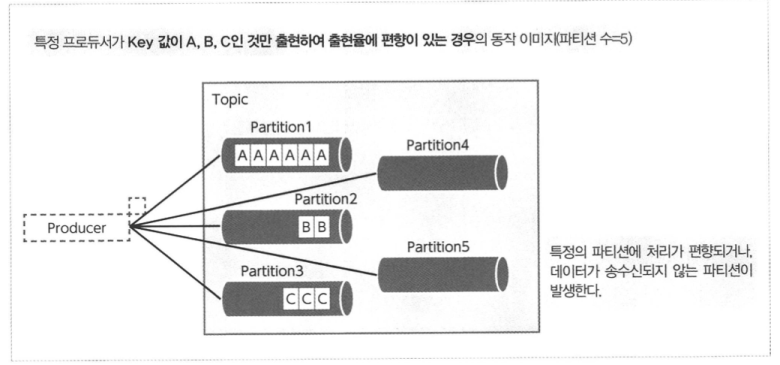
- 파티셔닝을 이용하는 경우, 데이터 편차에 따른 파티션의 편향에 주의해야 한다.
- 극단적인 경우에는 파티션 편향으로 인해 리소스를 부분적으로 사용할 수 없는 상태가 된다.
메세지의 순서 보증
- 카프카는 기본적으로 파티션을 여러 개로 구성하여 확장성을 높인다.
- 이로 인해, 프로듀서에서 메세지를 송신한 순서대로 컨슈머에서 메세지를 수신한다는 보장이 없다.
- 메세지 순서 보증을 위해 단일 파티션으로 구성하게 되면 카프카의 강점인 확장성을 잃게 된다.
- 메세지의 종류(토픽)별 순서를 보증하기 위해서는 파티셔닝에서 살펴본 ‘해시에 의한 분할’을 활용할 수 있다.
- 전체 메세지의 순서를 보증하는 것은 구현 난이도가 높다.
- 또한, 컨슈머 구현이 프로듀서 데이터 전송 순서에 의존하게 되면 카프카 전후의 시스템적인 분리에 제한을 줄 수 있다.
- 메세지 순서 보증을 위한 정렬 기능을 구현해야 한다면, 어디에서(브로커 or 컨슈머) 구현할지는 시스템 전체를 고려하여 판단해야 한다.
4. 컨슈머
컨슈머 API를 이용해 브로커에서 메세지를 취득하도록 구현된 애플리케이션이다.
PULL 형
브로커에 있는 메세지를 컨슈머가 취득해가는 방식(PULL 형)의 이점을 살펴보자.
- 컨슈머 시스템이 다운되거나 일시적으로 이상이 있어도 브로커에 미치는 영향이 적다.
- 만약 브로커에서 컨슈머로 PUSH 해주는 방식이라면, 컨슈머의 장애를 매번 브로커에서 대응해줘야 한다.
- 카프카를 경유하는 메세지와 후속 시스템이 많을수록 시스템 운용 부하, 성능 부하로 이어질 수 있다.
- 컨슈머가 주체적으로 데이터를 수신, 진행 관리하기 때문에, 후속 시스템의 확장과 축소가 쉽다.
컨슈머의 메세지 취득
- 메세지 취득은 브로커의 디스크에 보관되어 있는 동안 가능하다.
- 컨슈머는 취득 대상의 토픽과 파티션에 대해 Current Offset ~ LEO까지 취득을 요청한다.
- 이것을 반복함으로써 게속적인 메세지 취득을 할 수 있다.
- 메세지의 유입 빈도가 동일한 경우, 요청 간격이 길수록 모인 메세지가 많아진다.
- 일정 간격을 두고 요청함으로써 처리량을 높일 수 있다.
- 프로듀서의 배치 처리와 마찬가지로, 처리량과 지연 시간의 트레이드 오프를 고려한 설계가 필요하다.
컨슈머의 롤백
- Offset Commit을 통해 컨슈머 처리 실패, 고장 시 롤백 메세지 재취득을 할 수 있다.
- 컨슈머에 의한 데이터 취득이 2회 발생하는 다음과 같은 시나리오를 살펴보자.

- 위 시나리오의 4번에서 Current Offset이 Commit Offset까지 되돌아온 만큼의 메세지(6,7,8)에 대한 대처는 컨슈머 측에게 맡긴다.
- 즉, 재송신된(At Least Once) 메세지 6,7,8에 대해 어떻게 메세지 중복 처리를 할 것인지에 대한 방안이 필요하다.
데이터의 견고성을 높이는 복제 구조
카프카는 장애시에도 수신한 메세지를 잃지 않기 위해 복제(Replication) 구조를 갖추고 있다.
- 파티션은 단일 또는 여러 개의 레플리카로 구성되어 토픽 단위로 레플리카 수를 지정할 수 있다.
- 레플리카 중 하나는 Leader 나머지는 Follower라고 불린다.
- Follower는 Leader로부터 메세지를 취득하여 복제를 유지한다.
- 프로듀서/컨슈머간 데이터 교환은 Leader가 맡게된다.

In-Sync Replica
- Leader 레플리카의 복제 상태를 유지하고 있는 레플리카는
In-Sync Replica(ISR)로 분류된다.- 파라미터
replica.lag.time.max.ms에서 정한 시간보다도 오랫동안 복제의 요청 및 복제가 이루어지지 않을 경우 Leader 레플리카 복제 상태를 유지하지 않는 레플리카로 간주한다.
- 파라미터
- 모든 레플리카가 ISR로 되어 있지 않은 파티션을 Under Replicated Partitions라고 한다.
- 복제 수와는 별개로 최소 ISR 수
(min.insync.replica)설정이 가능하다.

High Watermark
- 복제가 완료된 최신 오프셋
- 컨슈머는 High Watermark까지 기록된 메세지를 취득할 수 있다.

Ack 설정
- 브로커 → 프로듀서로 Ack를 어느 타이밍에 송신할 것인지를 설정하는 것은 성능과 (브로커 서버 장애시) 데이터 유실 방지에 큰 영향을 준다.
| Ack 설정 | 설명 |
|---|---|
| 0 | 프로듀서는 Ack를 기다리지 않고 다음 메세지를 송신한다. |
| 1 | Leader Replica에 메세지가 전달되면 Ack를 반환한다. |
| all | 모든 ISR의 수만큼 복제되면 Ack를 반환한다. |
- 프로듀서는 Ack가 돌아오지 않고 타임아웃된 메세지에 대해 송신 실패로 간주한다.
- Ack를 반환하는 타이밍에는 메세지가 디스크가 아닌 메모리(OS 버퍼)에 기록되어있는 상태이다.
ISR과 Ack를 통한 메세지 처리 제어
ISR과 Ack 설정에 따라 메세지 쓰기를 제어할 수 있다.
상황은 브로커 4대, 레플리카 수는 3으로 브로커 1대가 고장나 레플리카를 하나 잃어버린 경우라고 가정한다.
1. min.insync.replicas=3 (레플리카 수와 동일), Ack=all
- 비정상 상태로 간주되어 잃어버린 레플리카가 ISR로 복귀할 때까지 메세지를 처리하지 않는다.

2. min.insync.replicas=2, Ack=all
- 브로커 1대가 고장나더라도 최소 ISR 수를 만족하므로 Ack를 반환하고 처리를 계속한다.
- 처리를 계속할 수는 있지만, 복구 전에 브로커가 더 고장나게 되면 처리 중인 메세지를 손실할 위험이 높아진다.

- 시스템 요구 사항과 제약 조건에 따라, ‘메세지를 잃지 않는 것’과 ‘시스템의 처리가 계속 되는 것’ 사이의 균형을 min.insync.replicas와 Ack 설정을 통해 조절해야 한다.
참고자료
- 사사키 도루 외 4인, 『실전 아파치 카프카』, 한빛미디어(2020), 2장