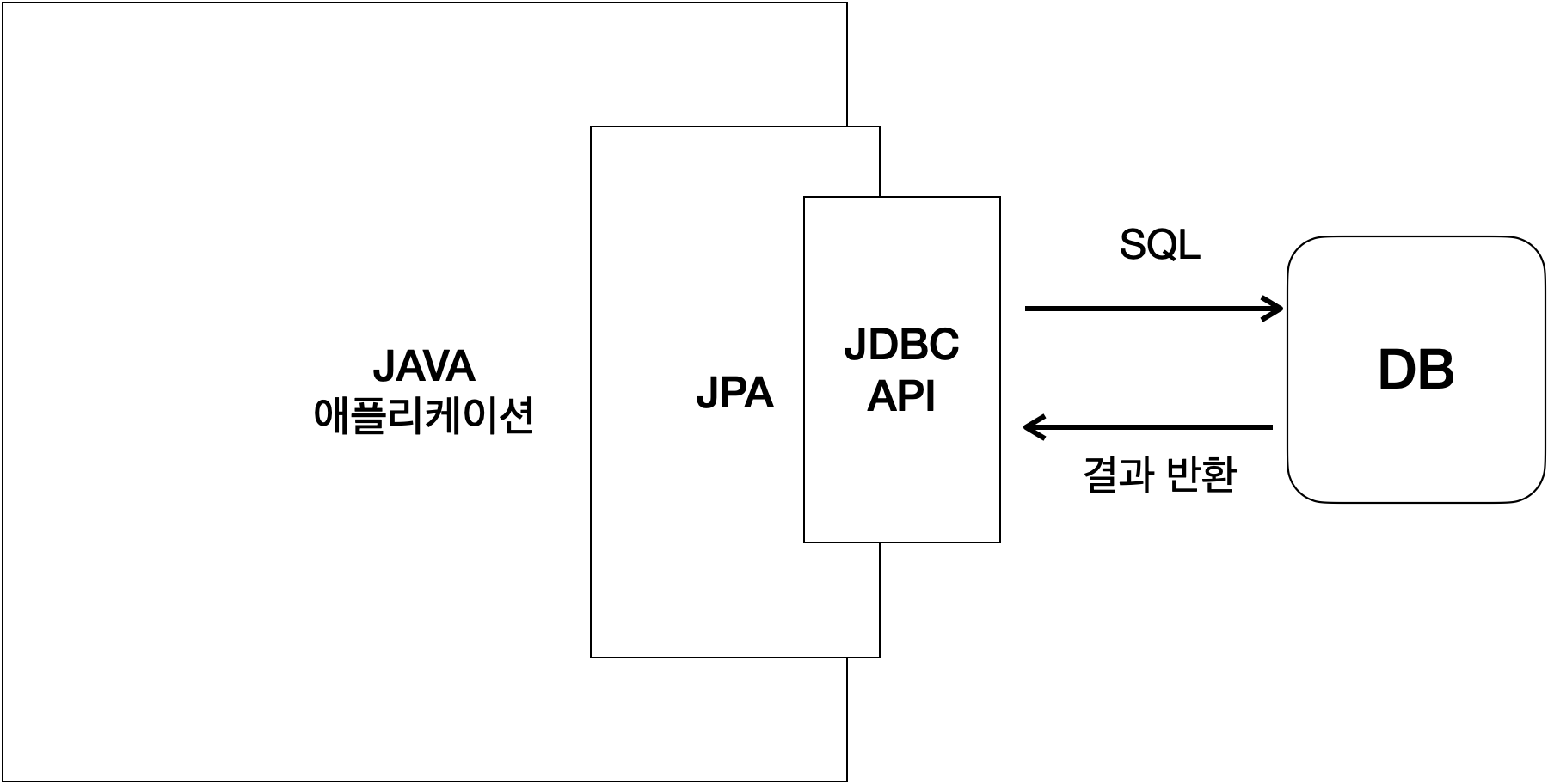
조회 결과에 섞여있는 모든 데이터를 Member, Team 각각의 객체에 알맞게 세팅한 뒤, Team 객체는 Member 객체에 세팅해줘야 한다.
따라서, 실무에서는 생산성을 위해 Member와 Team의 필드를 모두 합친 SuperDTO 등을 만들거나 하는 일이 비일비재하다.
1
2
3
4
5
6
7
8
9
10
11
12
13
publicMemberfind(StringmemberId){//SQL 실행 ...Membermember=newMember();//데이터베이스에서 조회한 회원 관련 정보를 모두 입력Teamteam=newTeam();//데이터베이스에서 조회한 팀 관련 정보를 모두 입력//회원과 팀 관계 설정member.setTeam(team);returnmember;}
classMemberService{...publicvoidprocess(){Membermember=memberDAO.find(memberId);member.getTeam();// 자유로운 객체 그래프 탐색member.getOrder().getDelivery();}}
3-4. 객체 비교
Without JPA
1
2
3
4
5
6
7
8
9
10
11
12
13
StringmemberId="100";Membermember1=memberDAO.getMember(memberId);Membermember2=memberDAO.getMember(memberId);member1==member2;//다르다.classMemberDAO{publicMembergetMember(StringmemberId){Stringsql="SELECT * FROM MEMBER WHERE MEMBER_ID = ?";...//JDBC API, SQL 실행returnnewMember(...);}}
DB Isolation Level이 Read Committed라도 애플리케이션에서 Repeatable Read를 보장한다.
1
2
3
4
5
StringmemberId="100";Memberm1=jpa.find(Member.class,memberId);//SQLMemberm2=jpa.find(Member.class,memberId);//캐시println(m1==m2)//true// 결과적으로는 SQL 1번만 실행
2. 트랜잭션을 지원하는 쓰기 지연(transactional write-behind)
트랜잭션을 커밋할 때까지 INSERT SQL을 모음
JDBC BATCH SQL 기능을 사용해서 한번에 SQL 전송
1
2
3
4
5
6
7
8
9
transaction.begin();// 트랜잭션 시작em.persist(memberA);em.persist(memberB);em.persist(memberC);//여기까지 INSERT SQL을 데이터베이스에 보내지 않는다.//커밋하는 순간 데이터베이스에 INSERT SQL을 모아서 보낸다.transaction.commit();// 트랜잭션 커밋
3. 지연 로딩과 즉시 로딩
옵션을 통해 지연 로딩과 즉시 로딩을 자유롭게 선택할 수 있다. 만약 SQL 중심이었다면 관련된 쿼리를 모두 변경해야 했을 것이다.
지연로딩 : 객체가 실제 사용될 때 로딩
1
2
3
Membermember=memberDAO.find(memberId);// SELECT * FROM MEMBERTeamteam=member.getTeam();StringteamName=team.getName();// SELECT * FROM TEAM
즉시 로딩: JOIN SQL로 한번에 연관된 객체까지 미리 조회
1
2
3
Membermember=memberDAO.find(memberId);// SELECT * FROM M.*, T.* FROM MEMBER JOIN TEAM ...Teamteam=member.getTeam();StringteamName=team.getName();