
Debezium
Debezium은 CDC(Change Data Capture)를 위한 오픈 소스 분산 플랫폼이다. (공식 사이트)
Kafka Connect의 Source Connector 플러그인 중 하나 (내가 지금까지 이해한 정도)
- Debezium은 Kafka Connect와 호환되는 소스 커넥터(Source Connector)들을 제공한다.
- 각 커넥터는 특정 DBMS와 연동되며, DBMS에서 발생하는 데이터 변경 사항을 실시간으로 감지하여 그 기록을 Kafka 토픽으로 스트리밍한다.
- 그 후, 애플리케이션은 Kafka 토픽에 저장된 이벤트 레코드들을 읽어서 해당 변경 내역을 처리할 수 있습니다.
- Kafka를 활용함으로써, Debezium은 애플리케이션이 데이터베이스에서 발생한 변경 사항을 정확하고 완전하게 소비할 수 있도록 한다.
- 애플리케이션이 갑작스럽게 중단되거나 연결이 끊기더라도, 그 기간 동안 발생한 이벤트를 놓치지 않는다.
- 애플리케이션이 다시 시작되면, 중단되었던 지점(topic의 offset 위치)부터 이어서 이벤트를 읽기 시작힌다.
아키텍처
- Debezium은 일반적으로 Kafka Connect를 통해 배포된다.
- Kafka Connect는 다음과 같은 작업을 구현하고 운영하기 위한 프레임워크이자 실행 환경이다:
- Debezium처럼 Kafka로 레코드를 전송하는 소스 커넥터(Source Connector)
- Kafka 토픽의 레코드를 다른 시스템으로 전달하는 싱크 커넥터(Sink Connector)
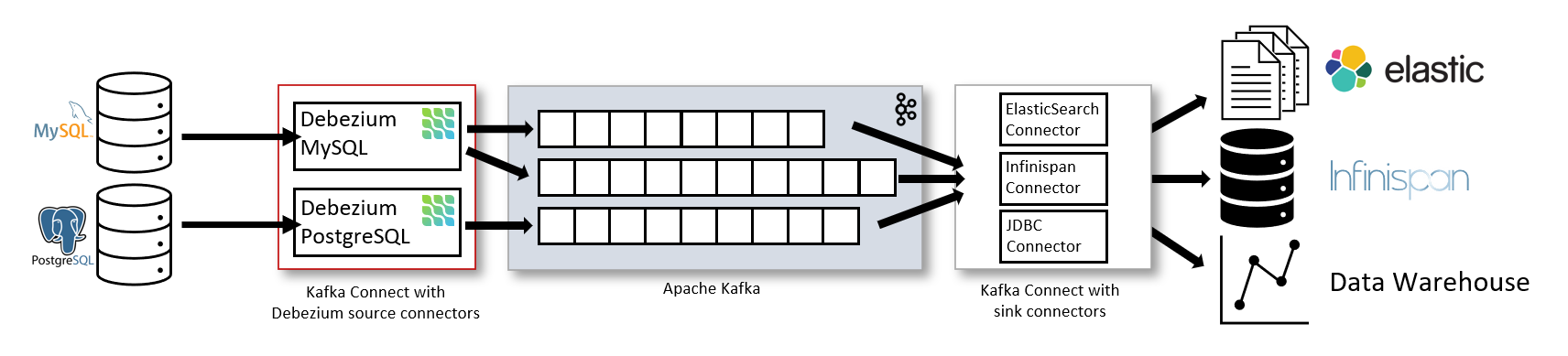 (출처 : https://debezium.io/documentation//reference/stable/architecture.html)
(출처 : https://debezium.io/documentation//reference/stable/architecture.html)
※ Debezium을 배포한다 ?
어떤 방식으로 CDC를 수행할지 정한 뒤, 그에 맞게 Debezium을 구성하고 실행 환경에 올리는 것을 의미한다. (참고)
- 예시:
| 배포 방식 | 실제로 하는 일 | 설명 |
|---|---|---|
| Kafka Connect 기반 배포 | Debezium 커넥터를 Kafka Connect 클러스터에 등록하고 실행 | 소스 커넥터로 DB의 변경사항을 읽어 Kafka에 넣음 |
| Debezium Server 배포 | Debezium Server 애플리케이션을 실행하고 환경 설정 지정 (예: DB 연결 정보, 메시징 대상) | Kafka 없이 Kinesis, Pub/Sub 등으로 CDC 스트리밍 |
| Debezium Engine 내장형 배포 | Java 애플리케이션에 Debezium 라이브러리를 포함시켜 코드 레벨에서 실행 | 앱 내부에서 CDC 수행 (Kafka Connect 불필요) |
1
2
3
4
5
6
7
# Kafka Connect 기반 Debezium 배포 예시
docker run -it --rm \
-e GROUP_ID=1 \
-e CONFIG_STORAGE_TOPIC=my_connect_configs \
-e OFFSET_STORAGE_TOPIC=my_connect_offsets \
-p 8083:8083 \
debezium/connect:latest
1
2
# Debezium Server 실행 예시
java -jar debezium-server.jar --config application.properties
MySQL 커넥터 등록하기
/connectorAPI를 호출해서 등록 (Kafka Connect REST API)
(참고 : Debezium, Kafka Connect, MySQL 버전 호환성 : https://debezium.io/releases/)
- 등록된 커넥터는 MySQL 서버의
binlog를 감시하기 시작한다.binlog에는 데이터베이스에서 발생한 모든 트랜잭션 기록(개별 행의 변경이나 스키마의 변경 등)이 저장된다.
- 커넥터는 이러한 변경을 감지하여 change event(변경 이벤트)를 생성한다.
- 앞으로의 예시에서는, Kafka가 자동으로 토픽을 생성하도록 설정되어 있으며, 각 토픽은 복제본(replica)이 1개뿐인 단순한 구성을 사용한다고 가정한다.
- 운영 환경에서는 보통 두 가지 방법 중 하나를 사용한다:
- Kafka 도구(Kafka CLI 등)를 이용해 필요한 토픽을 수동으로 생성하고, 복제(replica) 개수 같은 세부 설정을 직접 지정
- Kafka Connect 설정을 통해, 자동으로 생성되는 토픽의 설정을 커스터마이징
- 예시:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
$ curl -i -X POST -H "Accept:application/json" -H "Content-Type:application/json" localhost:8083/connectors -d
'{
"name": "inventory-connector",
"config": {
"connector.class": "io.debezium.connector.mysql.MySqlConnector",
"tasks.max": "1",
"database.hostname": "mysql",
"database.port": "3306",
"database.user": "debezium",
"database.password": "dbz",
"database.server.id": "184054",
"topic.prefix": "dbserver1",
"database.include.list": "inventory",
"schema.history.internal.kafka.bootstrap.servers": "kafka:9092",
"schema.history.internal.kafka.topic": "schema-changes.inventory"
}
}'
(Request Body에 담긴) 커넥터 관련 속성값들을 살펴보자.
name
커넥터의 이름
- 커넥터 인스턴스를 구분하기 위한 고유한 이름을 지정
config
커넥터가 어떻게 동작할지를 정의하는 세부 설정 항목들
(참고 : MySQL connector configuration properties)
tasks.max
커넥터가 생성할 수 있는 최대 태스크(task)의 개수
- Kafka Connect 서비스는 커넥터를 통해 하나 이상의 태스크를 실행할 수 있으며, 실행 중인 태스크들을 Kafka Connect 클러스터 내의 여러 노드에 자동으로 분산 배치한다.
- 만약 어떤 서비스가 중지되거나 충돌하더라도, 해당 태스크는 자동으로 다른 실행 중인 서비스로 재할당된다.
- 다만, MySQL 커넥터는 항상 단일 태스크만 사용하기 때문에 이 기본값을 변경해도 아무런 효과가 없다.
※ 단일 태스크 사용 이유
- Debezium MySQL Connector는 MySQL에 replication 클라이언트(slave)로 연결해서 binlog dump 프로토콜(replication 프로토콜의 일부)을 통해 변경 이벤트를 받는다.
- 이 스트림은 하나의 연속된 이벤트 스트림이므로, 여러 태스크가 나눠서 병렬로 읽을 수 있는 구조가 아니다.
- 만약 여러 태스크가
binlog를 병렬로 읽는다면, 동일한 트랜잭션 이벤트가 서로 다른 태스크로 분산되어 순서가 깨질 수 있다.
database.hostname
데이터베이스 호스트명
- Docker를 사용하는 경우, MySQL 서버를 실행하는 Docker 컨테이너 이름이다.
- 만약 MySQL이 일반적인 네트워크 환경(즉, Docker가 아닌)에서 실행 중이라면, MySQL 서버의 IP 주소나 DNS로 해석 가능한 호스트 이름을 지정해야 한다.
database.server.id
Debezium 커넥터(MySQL 클라이언트)의 고유 숫자 ID
- 지정된 ID는 현재 MySQL 클러스터 내에서 실행 중인 모든 데이터베이스 프로세스와 중복되지 않아야한다.
- 앞서 살펴본바와 같이, Debezium MySQL 커넥터는 MySQL의 replication 기능을 이용해서
binlog를 읽는다.- 즉, Debezium은 MySQL 입장에서 보면 하나의 복제 서버처럼 동작한다.
- MySQL 복제 환경에서는 각 서버(마스터, 슬레이브 등)가 서로를 구분하기 위해
server_id를 사용한다. - 따라서 Debezium 커넥터도
database.server.id값을 통해 자신을 MySQL 클러스터 내에서 고유하게 식별해야 한다.
- 이 값이 중복되면 MySQL이 “같은 ID의 클라이언트가 이미 연결되어 있다”며 복제를 거부한다.
topic.prefix
데이터베이스 서버 또는 클러스터를 구분하기 위한 네임스페이스(namespace)를 지정하는 문자열
- 이 값은 Kafka 토픽 이름의 접두사로 사용되며, 커넥터가 생성하는 모든 이벤트 토픽 이름이 이 값을 기반으로 만들어진다.
- 따라서 각 커넥터마다 이 값은 고유해야 한다.
- 영문자, 숫자, 하이픈(
-), 점(.), 밑줄(_)만 사용할 수 있다. - 예를 들어,
topic.prefix가dbserver1이라면dbserver1.inventory.customers,dbserver1.inventory.orders과 같이 토픽이 생성된다.
database.include.list
커넥터가 변경 사항을 캡처할 데이터베이스 이름을 지정 (필수 옵션은 아님)
- 쉼표(
,)로 구분된 정규식 목록으로 작성한다. - 커넥터는 이 리스트에 명시된 이름과 일치하는 데이터베이스의 변경만 캡처하며, 여기에 포함되지 않은 데이터베이스의 변경 사항은 캡처하지 않는다.
- 기본적으로(즉, 이 값을 지정하지 않은 경우), 커넥터는 모든 데이터베이스의 변경 사항을 캡처한다.
schema.history.internal.kafka.bootstrap.servers
커넥터가 Kafka 클러스터에 초기 연결을 맺을 때 사용할 호스트/포트 쌍 목록
- 이 연결은 두 가지 목적으로 사용된다:
- 커넥터가 이전에 Kafka에 저장한 데이터베이스 스키마 이력을 가져올 때
- 소스 데이터베이스에서 읽어들인 DDL문을 Kafka에 기록할 때
- 따라서 이 설정은 데이터 변경 이벤트용 Kafka 연결과는 별개로, 스키마 이력 관리용 Kafka 연결을 정의하는 것이다.
schema.history.internal.kafka.topic
커넥터가 데이터베이스 스키마 변경 이력을 저장하는 Kafka 토픽의 전체 이름을 지정
- Debezium은 단순히 데이터의 변경만 캡처하지 않고, 테이블 구조도 함께 추적한다.
- 예를 들어,
ALTER TABLE customers ADD COLUMN phone VARCHAR(20);- 이때 Debezium은 단순히 customers 테이블의 데이터만 바뀌었다고 알리는 게 아니라, “이 시점에 테이블 구조가 이렇게 바뀌었음” 이라는 스키마 변경 이력을 별도의 토픽에 기록해 둔다.
- 이렇게 해야 Debezium이 재시작되거나 장애 복구 후에도 정확한 스키마 정보로
binlog를 다시 해석할 수 있습니다.
| 역할 | 설명 |
|---|---|
| DDL 기록 | 테이블 생성, 삭제, 컬럼 추가/변경 등의 DDL 문을 저장 |
| 스키마 복원 | 커넥터가 재시작되면, 이 토픽에서 과거 스키마를 불러와 재구성 |
| 이벤트 해석 기준 | binlog의 각 이벤트를 당시의 테이블 구조에 맞게 해석하기 위함 |
| 내부 관리용 | 이 토픽은 보통 내부 관리용이므로 외부 애플리케이션이 구독하지 않음 |
- Debezium은 내부적으로 이런 흐름을 가진다:
1
2
3
4
5
6
7
8
9
MySQL binlog
↓
Debezium Connector
├─ DDL 감지 (스키마 변경)
├─ DML 감지 (데이터 변경)
↓
Kafka
├─ schema-changes.inventory ← 스키마 이력 저장
└─ dbserver1.inventory.customers ← 데이터 변경 이벤트 저장
변경 이벤트 살펴보기
dbserver1.inventory.customers토픽 가정
- 각 이벤트는 두 개의 JSON 데이터로 구성된다:
Key: 해당 행의 기본 키 정보Value: 실제 데이터 변경 내용
- JSON 데이터는 두 부분으로 구성된다:
schema:payload의 구조를 설명하는 Kafka Connect 스키마 정의payload: 실제 데이터 값
Create Event
- Key
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
{
"schema": {
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
}
],
"optional": false,
"name": "dbserver1.inventory.customers.Key"
},
"payload": {
"id": 1004
}
}
- Value
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
{
"schema": {
"type": "struct",
"fields": [
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
},
{
"type": "string",
"optional": false,
"field": "first_name"
},
{
"type": "string",
"optional": false,
"field": "last_name"
},
{
"type": "string",
"optional": false,
"field": "email"
}
],
"optional": true,
"name": "dbserver1.inventory.customers.Value",
"field": "before"
},
{
"type": "struct",
"fields": [
{
"type": "int32",
"optional": false,
"field": "id"
},
{
"type": "string",
"optional": false,
"field": "first_name"
},
{
"type": "string",
"optional": false,
"field": "last_name"
},
{
"type": "string",
"optional": false,
"field": "email"
}
],
"optional": true,
"name": "dbserver1.inventory.customers.Value",
"field": "after"
},
{
"type": "struct",
"fields": [
{
"type": "string",
"optional": true,
"field": "version"
},
{
"type": "string",
"optional": false,
"field": "name"
},
{
"type": "int64",
"optional": false,
"field": "server_id"
},
{
"type": "int64",
"optional": false,
"field": "ts_sec"
},
{
"type": "string",
"optional": true,
"field": "gtid"
},
{
"type": "string",
"optional": false,
"field": "file"
},
{
"type": "int64",
"optional": false,
"field": "pos"
},
{
"type": "int32",
"optional": false,
"field": "row"
},
{
"type": "boolean",
"optional": true,
"field": "snapshot"
},
{
"type": "int64",
"optional": true,
"field": "thread"
},
{
"type": "string",
"optional": true,
"field": "db"
},
{
"type": "string",
"optional": true,
"field": "table"
}
],
"optional": false,
"name": "io.debezium.connector.mysql.Source",
"field": "source"
},
{
"type": "string",
"optional": false,
"field": "op"
},
{
"type": "int64",
"optional": true,
"field": "ts_ms"
},
{
"type": "int64",
"optional": true,
"field": "ts_us"
},
{
"type": "int64",
"optional": true,
"field": "ts_ns"
}
],
"optional": false,
"name": "dbserver1.inventory.customers.Envelope",
"version": 1
},
"payload": {
"before": null,
"after": {
"id": 1004,
"first_name": "Anne",
"last_name": "Kretchmar",
"email": "annek@noanswer.org"
},
"source": {
"version": "3.3.1.Final",
"name": "dbserver1",
"server_id": 0,
"ts_sec": 0,
"gtid": null,
"file": "mysql-bin.000003",
"pos": 154,
"row": 0,
"snapshot": true,
"thread": null,
"db": "inventory",
"table": "customers"
},
"op": "r",
"ts_ms": 1486500577691,
"ts_us": 1486500577691547,
"ts_ns": 1486500577691547930
}
}
- 이 스키마는
dbserver1.inventory.customers.Envelope (version 1)라는 이름의 Kafka Connect 스키마를 포함하며, 다섯 가지 필드를 가진다:op: 이벤트가 어떤 작업(operation) 인지를 나타내는 문자열 값 (필수 필드)- c - create (INSERT)
- u - update
- d - delete
- r - read (스냅샷 시 기존 데이터 읽을 때)
before: 선택적(optional) 필드이며, 존재할 경우, 이벤트 발생 이전의 행(row) 상태를 포함after: 선택적 필드이며, 존재할 경우, 이벤트 발생 이후의 행(row) 상태를 포함source: 필수 필드이며, 이벤트의 출처(source) 메타데이터를 담고 있는 구조체- MySQL 커넥터의 경우, source 안에는 다음 정보들이 포함된다:
- 커넥터 이름 (dbserver1 등)
- 이벤트가 기록된 binlog 파일 이름
- 해당 이벤트가 binlog 내에서 나타난 위치(position)
- (한 binlog 이벤트에 여러 행이 있는 경우) 행의 인덱스
- 영향을 받은 데이터베이스 이름 및 테이블 이름
- 변경을 수행한 MySQL 스레드 ID
- 이 이벤트가 스냅샷 중 발생한 것인지 여부
- (가능한 경우) MySQL 서버 ID
- 이벤트가 기록된 타임스탬프 (초 단위)
- MySQL 커넥터의 경우, source 안에는 다음 정보들이 포함된다:
ts_ms: 선택적 필드이며, 존재할 경우 이 값은 커넥터가 이벤트를 처리한 시각(밀리초 단위)을 포함. 이 시간은 Kafka Connect 작업이 실행 중인 JVM의 시스템 시계 기준
※ Avro 고려하기
Avro는 데이터를 컴퓨터가 이해하고 저장/전송하기 쉬운 이진 형식으로 변환하는 ‘데이터 직렬화 시스템’이다.
JSON과 달리 스키마 진화(Schema Evolution)를 지원하여 데이터 구조 변경을 유연하게 처리할 수 있어 빅데이터 시스템에서 효율적으로 사용된다.
- Kafka Connect의 JSON 변환기는 모든 메시지마다 key와 value의 스키마 정의를 함께 포함하기 때문에, 이벤트 메시지가 매우 장황해진다.
- 이런 문제를 해결하기 위해 Apache Avro 포맷을 사용할 수도 있다.
- 즉, Kafka Connect 스키마를 Avro 스키마로 변환하고,
- 이 스키마는 별도의 Schema Registry 서비스에 저장되며,
- 실제 메시지에는 스키마 전체가 아니라 고유한 스키마 ID 와 Avro 인코딩된 바이너리 데이터만 포함된다.
- 이 방식 덕분에, 네트워크로 전송되거나 Kafka에 저장되는 메시지 크기가 JSON 포맷에 비해 훨씬 작아진다.
- 또한 Avro Converter는 스키마 진화(schema evolution) 기능을 지원하므로, Schema Registry에 각 스키마 버전의 변경 이력을 관리할 수도 있다.
Update Event
UPDATE customers SET first_name=’Anne Marie’ WHERE id=1004;
- Key : 전과 동일
- Value
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
{
"schema": {...},
"payload": {
"before": {
"id": 1004,
"first_name": "Anne",
"last_name": "Kretchmar",
"email": "annek@noanswer.org"
},
"after": {
"id": 1004,
"first_name": "Anne Marie",
"last_name": "Kretchmar",
"email": "annek@noanswer.org"
},
"source": {
"name": "3.3.1.Final",
"name": "dbserver1",
"server_id": 223344,
"ts_sec": 1486501486,
"gtid": null,
"file": "mysql-bin.000003",
"pos": 364,
"row": 0,
"snapshot": null,
"thread": 3,
"db": "inventory",
"table": "customers"
},
"op": "u",
"ts_ms": 1486501486308,
"ts_us": 1486501486308910,
"ts_ns": 1486501486308910814
}
}
Primary Key Update
- 기본 키 필드가 변경되는 경우에는 일반적인 UPDATE 이벤트 대신, 커넥터가 다음과 같은 두 개의 이벤트를 생성한다:
- 기존 키에 대한
DELETE이벤트 레코드 - 새(변경된) 키에 대한
CREATE이벤트 레코드
- 기존 키에 대한
- 두 이벤트는 일반적인 이벤트 구조와 내용을 가지지만, 기본 키 변경과 관련된 특수한 메시지 헤더가 추가로 포함된다.
DELETE이벤트 레코드에는__debezium.newkey라는 메시지 헤더가 포함된다.- 이 헤더의 값은 변경된 행의 새로운 primary key값
- 즉,
"이 행이 삭제되었지만, 사실은 새 키로 다시 생성될 것이다"라는 의미를 담고 있다.
CREATE이벤트 레코드에는__debezium.oldkey라는 메시지 헤더가 포함된다.- 이 헤더의 값은 업데이트 이전의(예전) 기본 키 값
- 즉,
"이 새 행은 이전에 이 키를 가진 행으로부터 온 것이다"라는 정보를 담고 있다.
Delete Event
DELETE FROM customers WHERE id=1004;
- 테이블에서 한 행(row)을 삭제하면, Debezium MySQL 커넥터는 두 개의 이벤트를 Kafka로 보낸다.
첫번째 이벤트
- Key 영역 : 전과 동일
- Value 영역
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
{
"schema": {...},
"payload": {
"before": {
"id": 1004,
"first_name": "Anne Marie",
"last_name": "Kretchmar",
"email": "annek@noanswer.org"
},
"after": null,
"source": {
"name": "3.3.1.Final",
"name": "dbserver1",
"server_id": 223344,
"ts_sec": 1486501558,
"gtid": null,
"file": "mysql-bin.000003",
"pos": 725,
"row": 0,
"snapshot": null,
"thread": 3,
"db": "inventory",
"table": "customers"
},
"op": "d",
"ts_ms": 1486501558315,
"ts_us": 1486501558315901,
"ts_ns": 1486501558315901687
}
}
두번째 이벤트
tombstone event : key는 동일하지만, value가 완전히 null인 이벤트
- Key : 전과 동일
- Value
1
2
3
4
{
"schema": null,
"payload": null
}
- Kafka는 log compaction이라는 기능을 가지고 있다.
- 이는 토픽 내 메시지를 key 기준으로 압축하는 기능이다.
- 각 key에 대해 가장 최신 메시지만 남기고, 이전 메시지들은 삭제할 수 있다.
삭제(delete)라는 개념을 표현하기 위해, Kafka는 key는 있고 value는null인 tombstone event를 사용한다.- Kafka는 이를 보고 “이 key에 대한 데이터는 삭제된 상태다”라고 인식하고, 해당 key의 이전 모든 메시지를 지운다.
- 즉시 삭제를 수행하지는 않고, Kafka의 log cleaner 스레드가 주기적으로 compaction을 수행할 때 처리된다.
- 즉, compaction이 실행되기 전까지는 tombstone과 이전 메시지 모두 로그에 남아 있을 수 있다.