
CDC(Change Capture Data)란 ?
데이터베이스나 데이터 웨어하우스 같은 데이터 소스의 모든 변경 사항을 추적하여, 이러한 변경 내용을 대상 시스템에 반영할 수 있도록 하는 과정
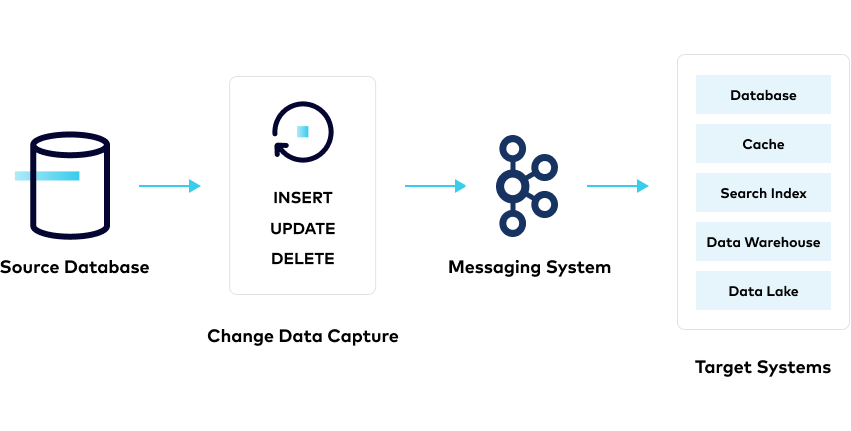 (출처 : https://www.confluent.io/learn/change-data-capture/#quick-intro-to-cdc)
(출처 : https://www.confluent.io/learn/change-data-capture/#quick-intro-to-cdc)
주요 이점
1. 대용량 일괄 업데이트 제거
- CDC는 변경된 데이터만을 증분 로드(incremental loading)하거나 실시간으로 스트리밍 방식으로 대상 저장소에 반영할 수 있다.
- 따라서 대규모 배치 업데이트가 필요하지 않다.
2. 로그 기반 효율성(Log-Based Efficiency)
- 로그 기반 CDC는 트랜잭션 로그에서 직접 변경 사항을 캡처하기 때문에 원본 시스템에 미치는 영향을 최소화한다.
3. 무중단 마이그레이션(Zero-Downtime Migrations)
- CDC가 제공하는 실시간 데이터 이동 기능은 무중단 데이터베이스 마이그레이션을 지원한다.
- 이를 통해 실시간 분석 및 리포팅에 필요한 최신 데이터를 이용할 수 있다.
4. 시스템 간 동기화(Synchronization Across Systems)
- CDC는 여러 시스템 간의 데이터를 동기화 상태로 유지한다. 이는 데이터 속도가 빠르고 즉각적인 의사결정이 필요한 환경에서 특히 중요하다.
5. 클라우드 및 스트림 처리 최적화(Optimized for Cloud and Stream Processing)
- CDC는 광역 네트워크(WAN)를 통해 데이터를 효율적으로 이동시킬 수 있어, 클라우드 환경 배포나 Apache Kafka와 같은 스트림 처리 솔루션과의 통합에 이상적이다.
구현 방식
CDC는 일반적으로 두 가지 주요 방식, Push 또는 Pull 방식으로 구현한다.
Push
- 소스 데이터베이스가 주요 역할을 담당한다.
- 즉, 데이터베이스 내에서 발생한 변경 사항을 직접 감지(capture)하고, 그 변경된 데이터를 대상 시스템으로 전송한다.
- 이 방식의 가장 큰 장점은 대상 시스템이 거의 실시간(near real-time)으로 최신 데이터를 받을 수 있다는 점이다.
- 데이터 변경이 발생하면 즉시 전송되므로, 지연이 최소화되고 데이터 일관성이 높게 유지된다.
- 하지만, 대상 시스템이 일시적으로 접속 불가하거나 오프라인 상태일 경우, 전송된 변경 데이터가 손실될 위험이 있다.
- 이러한 위험을 완화하기 위해, 일반적으로 소스와 대상 시스템 사이에 메시징 시스템을 둔다.
Pull
- 소스 데이터베이스가 변경 내용을 직접 전송하는 대신, 각 테이블에 있는 특정 컬럼(예:
last_updated나modified_at) 등에 데이터 변경 로그를 기록한다. - 그 후 대상 시스템이 주기적으로 소스 데이터베이스를 폴링(polling)하여 변경된 데이터를 감지하고 필요한 작업을 수행한다.
- 따라서 소스 시스템의 부하가 적고, 데이터베이스에 추가적인 부하 없이 간단하게 구현할 수 있다.
- 대상 시스템이 일시적으로 오프라인일 때 데이터 손실을 방지하기 위해 중간에 메시징 시스템을 두는 것이 일반적이다.
- 메시징 시스템은 변경 데이터를 임시 저장(버퍼링) 하여, 대상 시스템이 복구되면 안전하게 전달될 수 있도록 보장한다.
- 이 방식의 단점은 데이터 변경이 즉시 반영되지 않는다는 점이다.
- 대상 시스템이 일정 주기(예: 1분, 5분, 10분)에 한 번씩만 데이터를 가져오기 때문에, 그 사이에 발생한 변경 사항은 다음 폴링 시점까지 지연된다.
데이터 변경 감지 방식
1. Timestamp-based
테이블에
LAST_MODIFIED,LAST_UPDATED같은 타임스탬프 컬럼을 추가하여 각 레코드의 가장 최근 변경 시각을 기록하는 방식
- 대상 시스템은 이 컬럼을 조회해서 마지막 실행 이후 변경된 데이터를 가져온다.
- DELETE(삭제) 연산을 직접 감지할 수 없다. (즉, “소프트 삭제”만 가능 — 실제 삭제가 아닌 상태 플래그 업데이트 방식)
- 모든 행(row)을 스캔해야 하므로 소스 시스템 부하가 커질 수 있다.
- 어떤 데이터가 갱신되었는지를 확인하기 위해 전체 테이블을 조회해야 함.
- DB 스키마 변경이 필요하다. (
LAST_UPDATED컬럼 추가 등)
2. Trigger-based
데이터베이스가 제공하는 트리거(trigger) 기능을 활용. 즉, INSERT, UPDATE, DELETE가 실행될 때마다 자동으로 실행되는 프로시저를 등록
- 각 트리거는 변경된 데이터를 별도의 테이블(“shadow table” 또는 “event table”)에 기록한다.
- 필요하다면 메시징 시스템에 이벤트를 전송할 수도 있다.
- 소스 DB 성능에 부정적인 영향을 미친다. (한 번의 데이터 변경이 여러 번의 쓰기 작업으로 이어짐 — 원본 테이블 + 이벤트 테이블)
- DB 스키마 변경이 필요합니다. (트리거 및 이벤트 테이블 추가)
- 트리거가 많아질수록 관리 복잡도 증가 (테이블마다 3개씩 필요 — INSERT, UPDATE, DELETE)
3. Log-based
데이터베이스는 트랜잭션 수행 시마다 모든 변경사항을 트랜잭션 로그 파일(MySQL -
binlog, PostgreSQL -WAL, Oracle -redo log)에 기록
이 로그는 원래 복구 용도로 사용되지만, CDC 시스템이 이 로그를 읽어서 실시간으로 변경 사항을 감지할 수도 있다.
- 소스 데이터베이스에 부하를 거의 주지 않는다. (트랜잭션 로그를 읽기만 하므로 쿼리 실행 부담 없음)
- 모든 변경 유형(INSERT, UPDATE, DELETE)을 감지할 수 있다.
- DB 스키마를 변경할 필요가 없다.
- 트랜잭션 로그 형식이 표준화되어 있지 않다.
- 즉, DB 벤더(MySQL, Oracle, PostgreSQL 등)마다 로그 구조가 다르며, 버전별로 변경될 수 있다.
- 롤백된 변경 내역을 식별 및 제외해야 한다.
- 로그에는 커밋되지 않은 변경도 일시적으로 기록되기 때문에.